")
年末の2015年12月26日、第20回シェル芸勉強会に参加してきました。
で、その際の備忘録として、どんな感じで問題を解いていったか残しておくことにする。
なお、問題・解答などなどはこちらにあるので、お題用のファイルのダウンロード(github)含めまず参照。
Q1(各ファイルごとに最大の値を抽出)
file_A-*のグループ、file_B-*のグループからそれぞれ最大の数を探して、その値をグループごとに表示させるよ、という問題。
最初、for文使って解くんかいなと思ってたのだけどタイムオーバー。
模範解答のように、grepで空検索してファイル名を標準出力させて、それをsortさせて表示させる方が良いみたいだ。模範解答の通りにやるんじゃ進歩が無いので、最大値のみを表示させるのにteeコマンドを使ってみることにした。
…正直、あまりキレイに表示されないので、無駄な抗い感があるけど、まぁいいだろ。
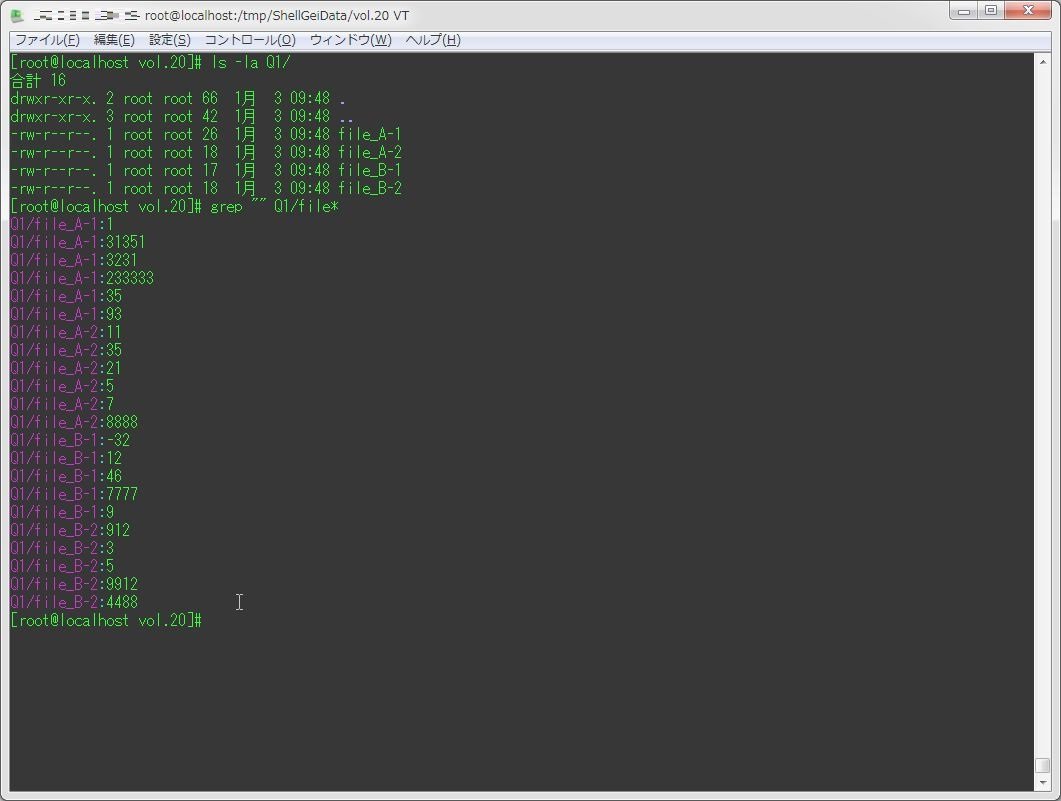
grep "" file_* | sed 's/\-.//g' | sort -t: -k1,1 -k2,2nr | tee >(grep file_A -m 1) >(grep file_B -m 1) > /dev/null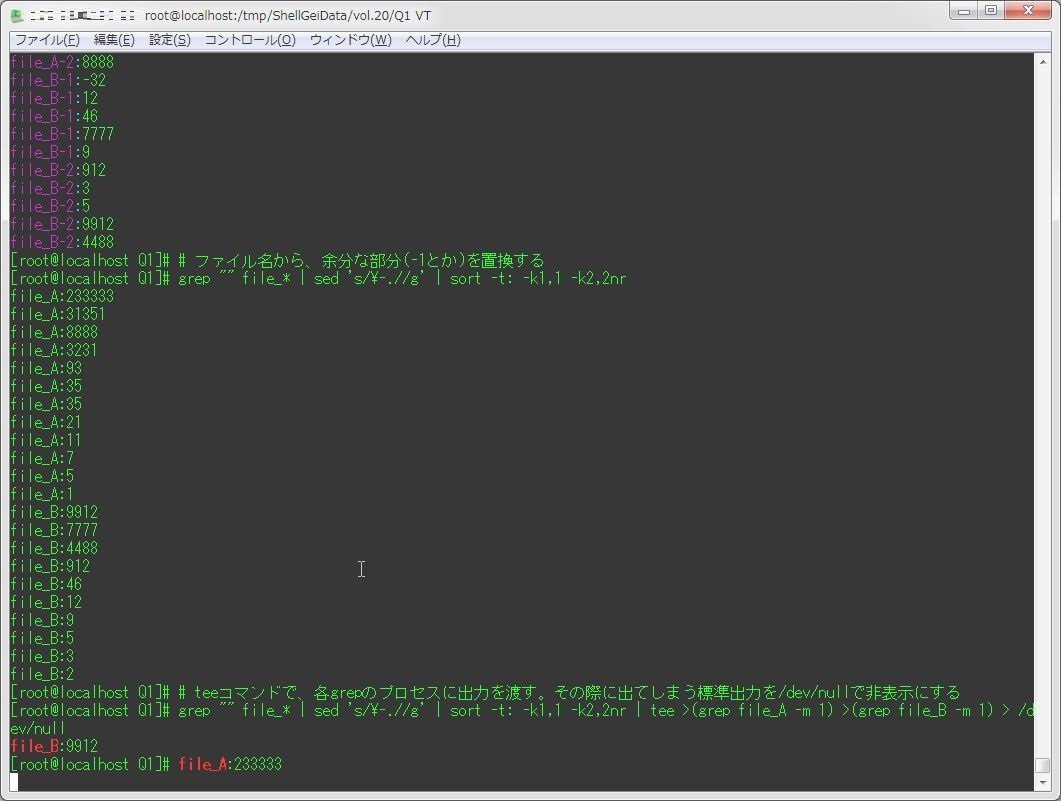
[root@localhost Q1]# # grepで、ファイル名:中身を標準出力で表示させる
[root@localhost Q1]# grep "" file_*
file_A-1:1
file_A-1:31351
file_A-1:3231
file_A-1:233333
file_A-1:35
file_A-1:93
file_A-2:11
file_A-2:35
file_A-2:21
file_A-2:5
file_A-2:7
file_A-2:8888
file_B-1:-32
file_B-1:12
file_B-1:46
file_B-1:7777
file_B-1:9
file_B-2:912
file_B-2:3
file_B-2:5
file_B-2:9912
file_B-2:4488
[root@localhost Q1]# # ファイル名から、余分な部分(-1とか)を置換する
[root@localhost Q1]# grep "" file_* | sed 's/\-.//g' | sort -t: -k1,1 -k2,2nr
file_A:233333
file_A:31351
file_A:8888
file_A:3231
file_A:93
file_A:35
file_A:35
file_A:21
file_A:11
file_A:7
file_A:5
file_A:1
file_B:9912
file_B:7777
file_B:4488
file_B:912
file_B:46
file_B:12
file_B:9
file_B:5
file_B:3
file_B:2
[root@localhost Q1]# # teeコマンドで、各grepのプロセスに出力を渡す。その際に出てしまう標準出力を/dev/nullで非表示にする
[root@localhost Q1]# grep "" file_* | sed 's/\-.//g' | sort -t: -k1,1 -k2,2nr | tee >(grep file_A -m 1) >(grep file_B -m 1) > /dev/null
file_B:9912
[root@localhost Q1]# file_A:233333見てわかるように、最終的な出力がちょっと汚い・・・
別のファイルに書き出すのなら、少しはキレイになるんだけど。。。グループが増えたらコードが汚くなるので良くない解き方かも・・・
GNU Parallel使えるなら、そっちで書いた方がキレイな気がする。
grep "" file_* | sed 's/\-.//g' | sort -t: -k1,1 -k2,2nr | tee >(grep file_A -m 1 >> /tmp/aaa) >(grep file_B -m 1 >> /tmp/aaa) > /dev/null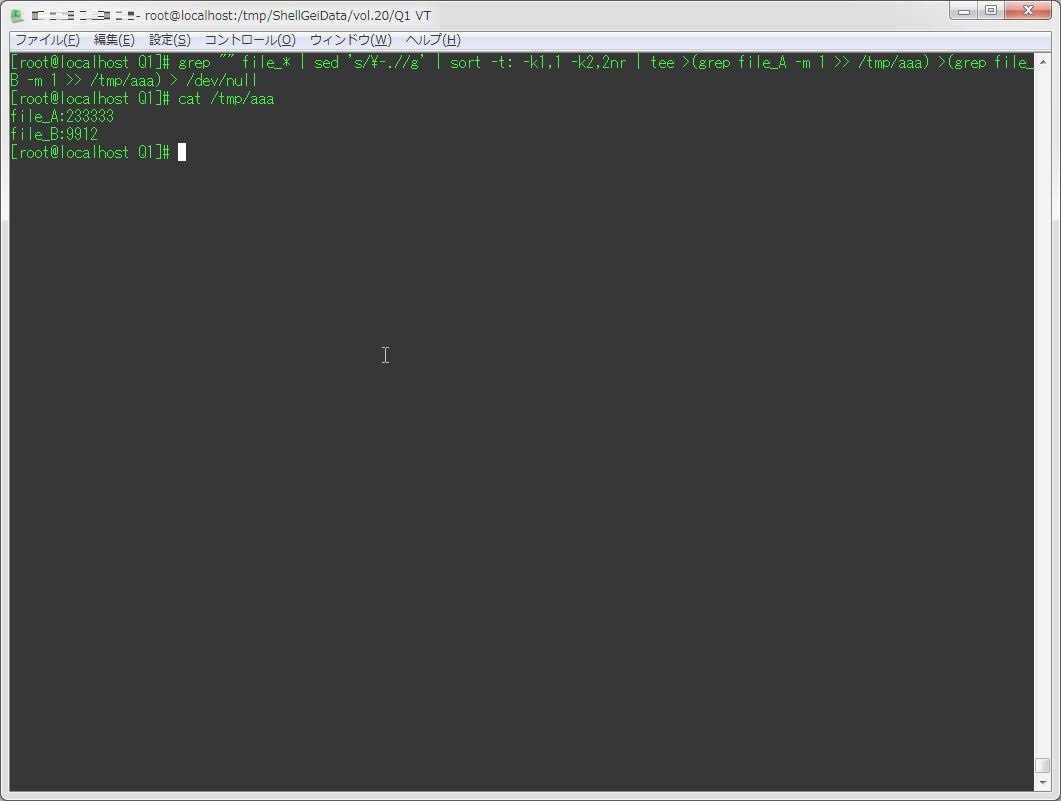
Q2(アンサイクロペディアのページにあるbashコードを端末上で実行させる)
アンサイクロペディアのシェル芸のページにある、カースト最上位者が日常的に書く、素数を出力するワンライナー」のコードをコマンドで取得し、それをコンソール上でそのままワンライナーで実行させるという問題。
ウェブスクレイピングの問題なんだけど、対象のページではevalという単語を持ってるのはその一行だけなので、まずはそれで取得、後はそれをbashに渡してあげるだけで実行できる。
curl -s http://ja.uncyclopedia.info/wiki/%E3%82%B7%E3%82%A7%E3%83%AB%E8%8A%B8 | grep eval | sed 's/^$.//g' | bash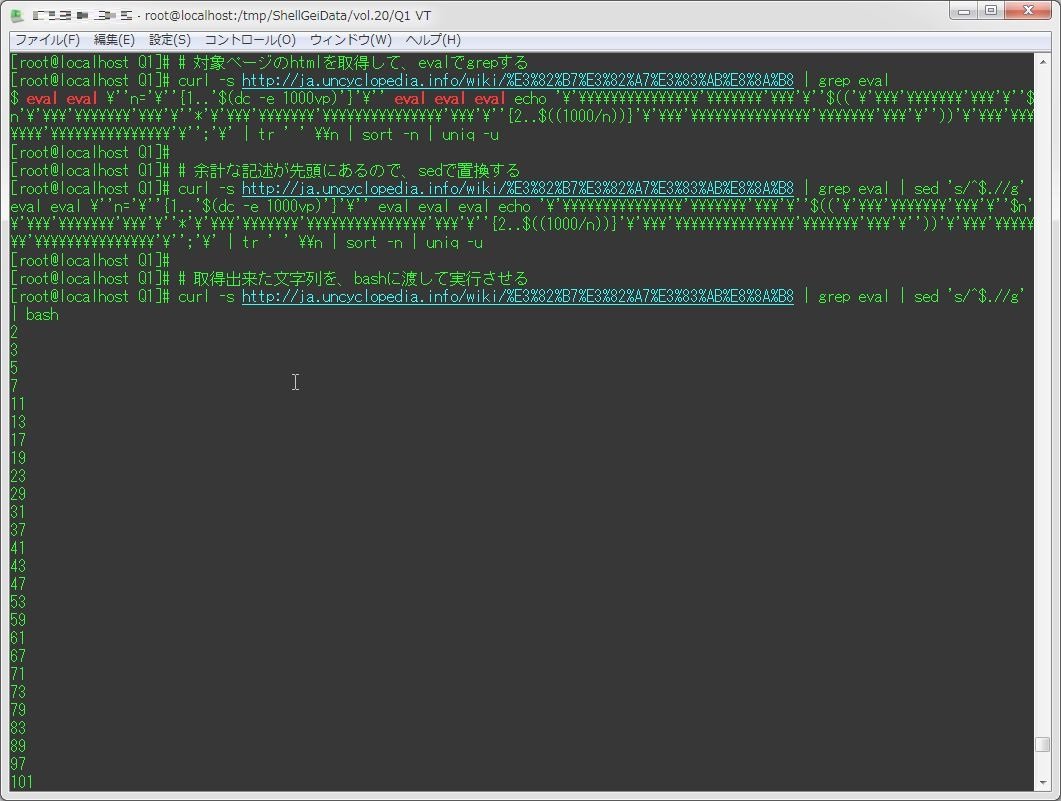
[root@localhost Q1]# # 対象ページのhtmlを取得して、evalでgrepする
[root@localhost Q1]# curl -s http://ja.uncyclopedia.info/wiki/%E3%82%B7%E3%82%A7%E3%83%AB%E8%8A%B8 | grep eval
$ eval eval \''n='\''{1..'$(dc -e 1000vp)'}'\'' eval eval eval echo '\'\\\\\\\\\\\\\\\'\\\\\\\'\\\'\''$(('\'\\\'\\\\\\\'\\\'\''$n'\'\\\'\\\\\\\'\\\'\''*'\'\\\'\\\\\\\'\\\\\\\\\\\\\\\'\\\'\''{2..$((1000/n))}'\'\\\'\\\\\\\\\\\\\\\'\\\\\\\'\\\'\''))'\'\\\'\\\\\\\'\\\\\\\\\\\\\\\'\'';'\' | tr ' ' \\n | sort -n | uniq -u
[root@localhost Q1]#
[root@localhost Q1]# # 余計な記述が先頭にあるので、sedで置換する
[root@localhost Q1]# curl -s http://ja.uncyclopedia.info/wiki/%E3%82%B7%E3%82%A7%E3%83%AB%E8%8A%B8 | grep eval | sed 's/^$.//g'
eval eval \''n='\''{1..'$(dc -e 1000vp)'}'\'' eval eval eval echo '\'\\\\\\\\\\\\\\\'\\\\\\\'\\\'\''$(('\'\\\'\\\\\\\'\\\'\''$n'\'\\\'\\\\\\\'\\\'\''*'\'\\\'\\\\\\\'\\\\\\\\\\\\\\\'\\\'\''{2..$((1000/n))}'\'\\\'\\\\\\\\\\\\\\\'\\\\\\\'\\\'\''))'\'\\\'\\\\\\\'\\\\\\\\\\\\\\\'\'';'\' | tr ' ' \\n | sort -n | uniq -u
[root@localhost Q1]#
[root@localhost Q1]# # 取得出来た文字列を、bashに渡して実行させる
[root@localhost Q1]# curl -s http://ja.uncyclopedia.info/wiki/%E3%82%B7%E3%82%A7%E3%83%AB%E8%8A%B8 | grep eval | sed 's/^$.//g' | bash
2
3
5
7
11
13
17
19
23
29
31
37
41
・・・Q3(ファイルに記述されている奇数と偶数をそれぞれ別々にソートする)
ファイルに偶数と奇数が記述されているので、奇数を1列目で昇順、偶数を2列目で降順といった形に編集して表示させる。
本番では全然解けなかったので、模範解答を分解して記述する。
1列のものを2列にするためには、pasteコマンドを用いると良いようだ。
paste <(awk '$1%2' Q3 | sort) <(awk '$1%2==0' Q3 | sort -r) | sed 's/\t/ /g'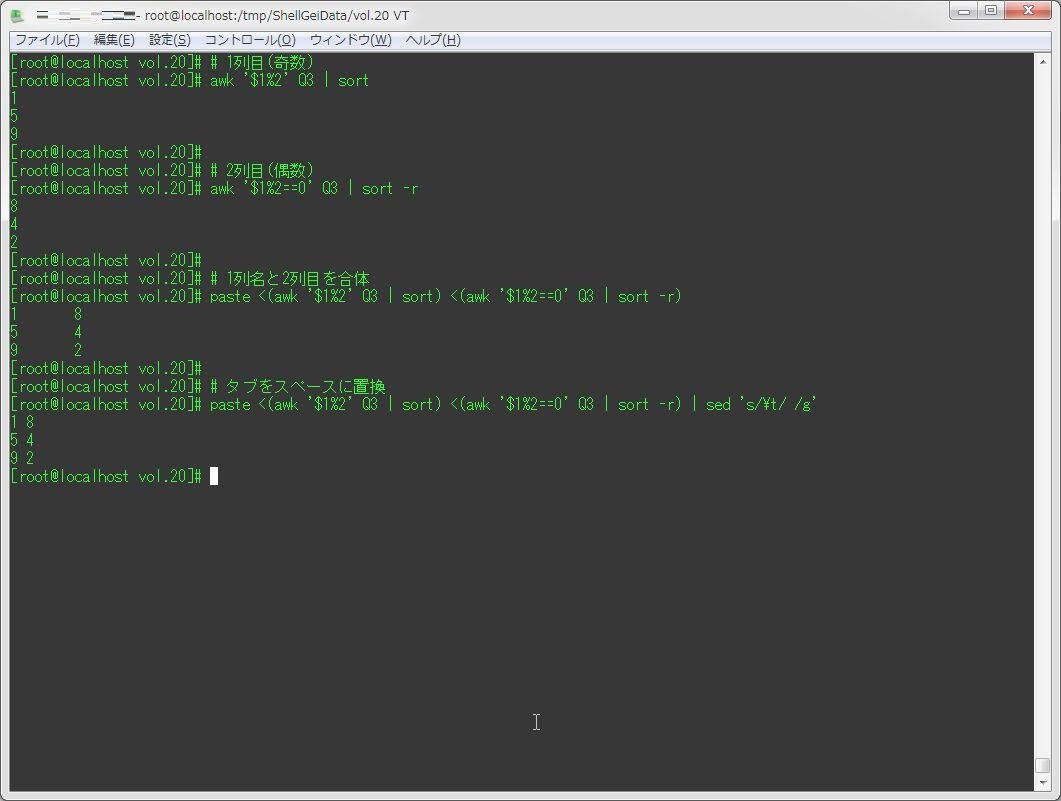
[root@localhost vol.20]# # 1列目(奇数)
[root@localhost vol.20]# awk '$1%2' Q3 | sort
1
5
9
[root@localhost vol.20]#
[root@localhost vol.20]# # 2列目(偶数)
[root@localhost vol.20]# awk '$1%2==0' Q3 | sort -r
8
4
2
[root@localhost vol.20]#
[root@localhost vol.20]# # 1列名と2列目を合体
[root@localhost vol.20]# paste <(awk '$1%2' Q3 | sort) <(awk '$1%2==0' Q3 | sort -r)
1 8
5 4
9 2
[root@localhost vol.20]#
[root@localhost vol.20]# # タブをスペースに置換
[root@localhost vol.20]# paste <(awk '$1%2' Q3 | sort) <(awk '$1%2==0' Q3 | sort -r) | sed 's/\t/ /g'
1 8
5 4
9 2
Q4(sshでログインしているターミナルを自分以外強制終了させる)
ワンライナーで、sshでログインしている自分以外のターミナルを強制的に終了(kill)させる、というもの。
個人的には、今回の勉強会で一番良く解けたような気がしないでもない。
当初、ttyコマンドで以下のようにして自身のターミナルを確認しようかと思ったのだが、どうもうまく動かない。
どうやら、以下のようにコマンドを実行するとターミナルと関係の無いプロセスでttyが実行されるため、思っていたように動作しないようだ。
[root@localhost vol.20]# who
root tty1 2016-01-03 09:04
root pts/0 2016-01-03 09:08 (172.28.XXX.XXX)
root pts/1 2016-01-04 01:25 (172.28.XXX.XXX)
root pts/2 2016-01-04 01:25 (172.28.XXX.XXX)
[root@localhost vol.20]#
[root@localhost vol.20]# tty | sed 's/\/dev\///g'
pts/0
[root@localhost vol.20]#
[root@localhost vol.20]# set -vx
printf "\033]0;%s@%s:%s\007" "${USER}" "${HOSTNAME%%.*}" "${PWD/#$HOME/~}"
++ printf '\033]0;%s@%s:%s\007' root localhost /tmp/ShellGeiData/vol.20
[root@localhost vol.20]# who | grep $(tty | sed 's/\/dev\///g')
who | grep $(tty | sed 's/\/dev\///g')
+ who
++ sed 's/\/dev\///g'
++ tty
+ grep --color=auto tty $'\343\201\247\343\201\257\343\201\202\343\202\212\343\201\276\343\201\233\343\202\223'
grep: ではありません: そのようなファイルやディレクトリはありません
printf "\033]0;%s@%s:%s\007" "${USER}" "${HOSTNAME%%.*}" "${PWD/#$HOME/~}"
++ printf '\033]0;%s@%s:%s\007' root localhost /tmp/ShellGeiData/vol.20f
このため、とりあえず以下のように最初にttyを実行することで端末情報を取得し、他の端末をkillした。
tty | sed 's/\/dev\///g' | xargs -I{} grep -v {} <(ps -uh) | awk '$0=$2' | xargs kill -KILL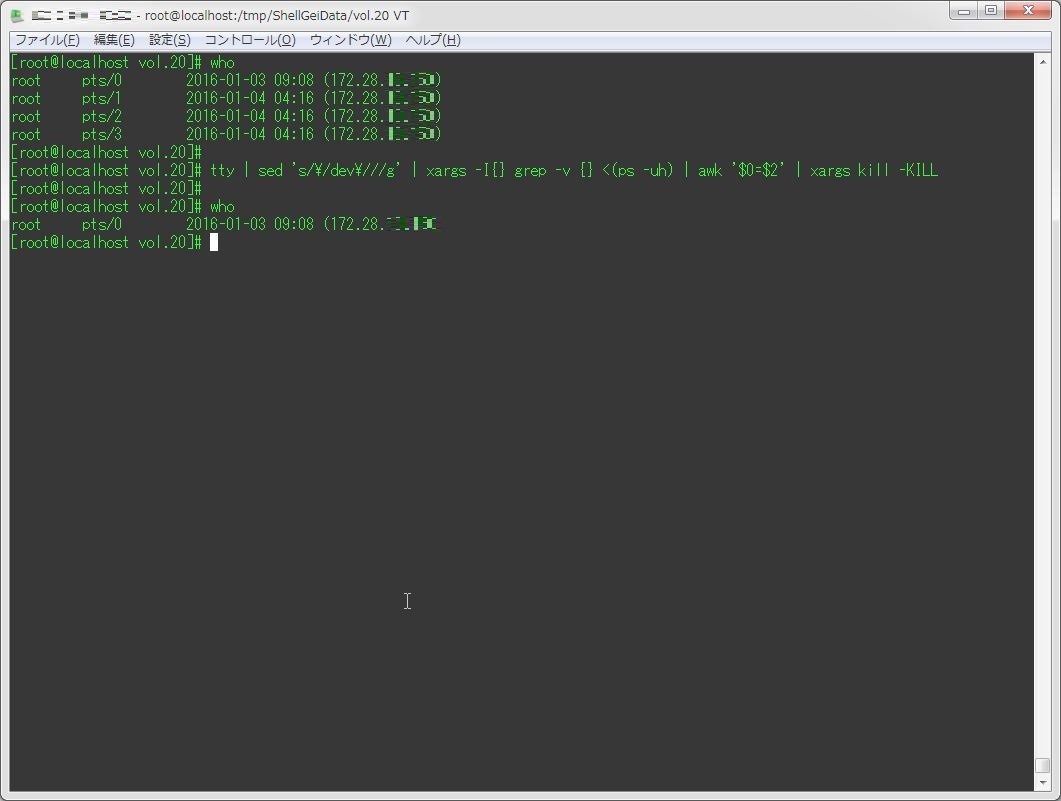
[root@localhost vol.20]# who
root pts/0 2016-01-03 09:08 (172.28.XXX.XXX)
root pts/1 2016-01-04 04:16 (172.28.XXX.XXX)
root pts/2 2016-01-04 04:16 (172.28.XXX.XXX)
root pts/3 2016-01-04 04:16 (172.28.XXX.XXX)
[root@localhost vol.20]#
[root@localhost vol.20]# tty | sed 's/\/dev\///g' | xargs -I{} grep -v {} <(ps -uh) | awk '$0=$2' | xargs kill -KILL
[root@localhost vol.20]#
[root@localhost vol.20]# who
root pts/0 2016-01-03 09:08 (172.28.XXX.XXX)で、とりあえずこの解答で満足していたのだけど、家に帰る途中に「そもそもシェル変数使えばもっと簡単なんじゃないの?」ということに気づいたので、それで作りなおしたのが以下。
grepもawkで実施させるようにしたのだけど、こっちの方が記述もキレイだし、本来あるべき記述だと思う。
ps -uh | awk '$7!="'${SSH_TTY/\/dev\//}'" {system("sudo kill -9 "$2)}' -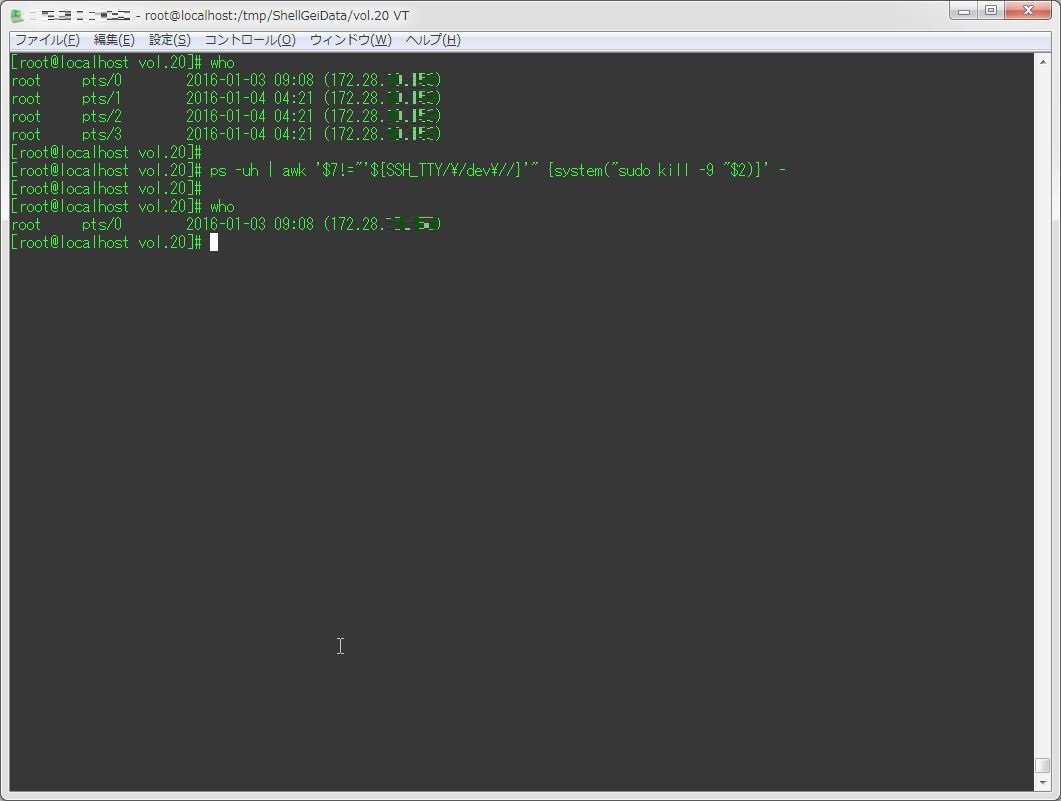
[root@localhost vol.20]# who
root pts/0 2016-01-03 09:08 (172.28.XXX.XXX)
root pts/1 2016-01-04 04:21 (172.28.XXX.XXX)
root pts/2 2016-01-04 04:21 (172.28.XXX.XXX)
root pts/3 2016-01-04 04:21 (172.28.XXX.XXX)
[root@localhost vol.20]#
[root@localhost vol.20]# ps -uh | awk '$7!="'${SSH_TTY/\/dev\//}'" {system("sudo kill -9 "$2)}' -
[root@localhost vol.20]#
[root@localhost vol.20]# who
root pts/0 2016-01-03 09:08 (172.28.XXX.XXX)Q5(最大公約数を求めるワンライナー)
任意の二つの自然数をechoして、最大公約数を求めるワンライナーを作るよ、という問題。
正直、全然わからんかったのだけど、ユークリッドの互除法をいい感じにコマンドに落としこむ事で解が得られるらしい。
で、模範解答ではこれをawkでやっているようだ。
echo 45 126 | awk '{while($1*$2!=0){if($1>$2){$1=$1-$2}else{$2=$2-$1}print}}' | awk 'END{print $1}'Q6(対象文字列が行の何列目にあるかを出力する)
ファイルの中に記述されている人の名前が、それぞれ何列目に記述されているのかをワンライナーで出力させる、という問題。
ぶっちゃけた話、これについても、これ以降の問題についてもあまり歯が立たなかった・・・。
というわけで、以降の問題については模範解答を分解してわかった気になってみる。
sed 's/ / /g' Q6 | awk '{for(i=1;i<=NF;i++){print $i,NR,i}}' | sort -k1,2 | awk '{print $1,$3}' | xargs -n 4 | awk '{print $1,$2,$4}'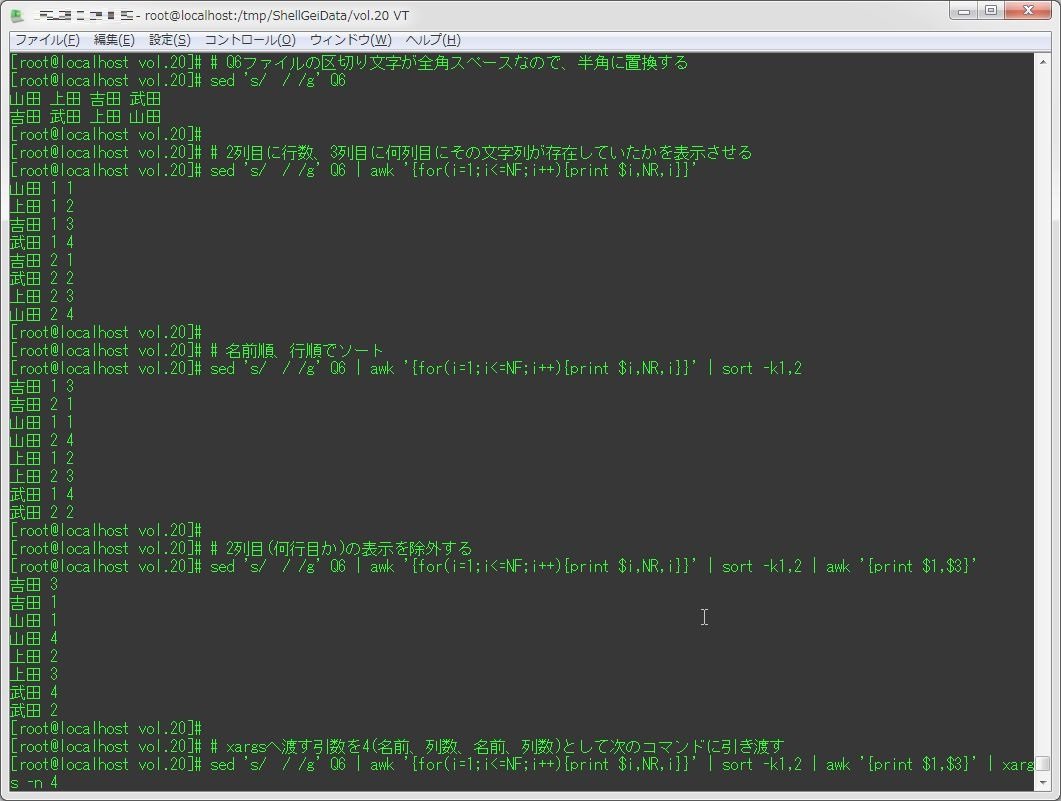
[root@localhost vol.20]# # Q6ファイルの区切り文字が全角スペースなので、半角に置換する
[root@localhost vol.20]# sed 's/ / /g' Q6
山田 上田 吉田 武田
吉田 武田 上田 山田
[root@localhost vol.20]#
[root@localhost vol.20]# # 2列目に行数、3列目に何列目にその文字列が存在していたかを表示させる
[root@localhost vol.20]# sed 's/ / /g' Q6 | awk '{for(i=1;i<=NF;i++){print $i,NR,i}}'
山田 1 1
上田 1 2
吉田 1 3
武田 1 4
吉田 2 1
武田 2 2
上田 2 3
山田 2 4
[root@localhost vol.20]#
[root@localhost vol.20]# # 名前順、行順でソート
[root@localhost vol.20]# sed 's/ / /g' Q6 | awk '{for(i=1;i<=NF;i++){print $i,NR,i}}' | sort -k1,2
吉田 1 3
吉田 2 1
山田 1 1
山田 2 4
上田 1 2
上田 2 3
武田 1 4
武田 2 2
[root@localhost vol.20]#
[root@localhost vol.20]# # 2列目(何行目か)の表示を除外する
[root@localhost vol.20]# sed 's/ / /g' Q6 | awk '{for(i=1;i<=NF;i++){print $i,NR,i}}' | sort -k1,2 | awk '{print $1,$3}'
吉田 3
吉田 1
山田 1
山田 4
上田 2
上田 3
武田 4
武田 2
[root@localhost vol.20]#
[root@localhost vol.20]# # xargsへ渡す引数を4(名前、列数、名前、列数)として次のコマンドに引き渡す
[root@localhost vol.20]# sed 's/ / /g' Q6 | awk '{for(i=1;i<=NF;i++){print $i,NR,i}}' | sort -k1,2 | awk '{print $1,$3}' | xargs -n 4
吉田 3 吉田 1
山田 1 山田 4
上田 2 上田 3
武田 4 武田 2
[root@localhost vol.20]#
[root@localhost vol.20]# # 3列目の表示を除外する
[root@localhost vol.20]# sed 's/ / /g' Q6 | awk '{for(i=1;i<=NF;i++){print $i,NR,i}}' | sort -k1,2 | awk '{print $1,$3}' | xargs -n 4 | awk '{print $1,$2,$4}'
吉田 3 1
山田 1 4
上田 2 3
武田 4 2Q7(「魚」という部分を持つ漢字をなるべく多く列挙する)
「魚」という字を含んでいる漢字を、一つでも多く出力させるという問題。
手法は問わないとなっているが、基本的にはWEBスクレイピングか日本語コードで該当する範囲の数字を文字列として出力させるというもの。
模範解答では後者の手法が取られている。
seq 39770 40058 | xargs printf "&#x%x;" | nkf --numchar-input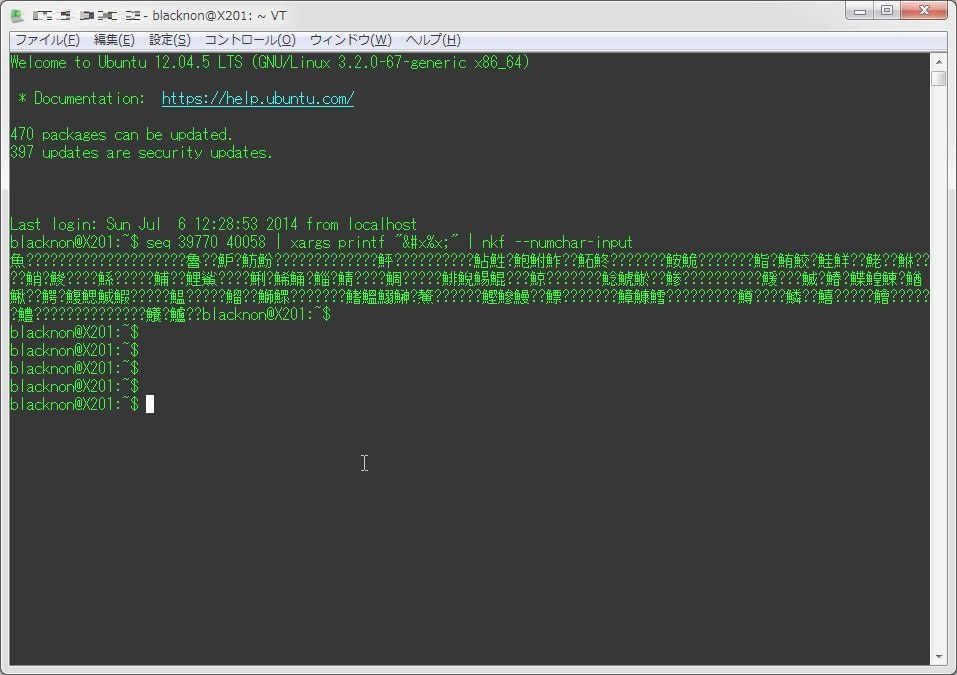
・・・まぁ、なんといいますか。
手元の環境だと全部の文字をちゃんと表示出来なかったので分かりにくいと思うのだけど、ちゃんと表示がされるのでご安心ください。
Q8(漢数字→アラビア数字の変換)
漢数字で書かれた内容をアラビア数字に変換する、というもの。
残念ながら、単体のコマンドを探して見たのだけど見つけられ無かった・・・
模範解答では一度sedで漢数字をアラビア数字に何も考えずに置換して、その後「十」とか「百」と言った漢字表記を別途計算する対応を行っている。
sed 'y/一二三四五六七八九/123456789/' Q8 | sed -e 's/十/1*10+/' -e 's/百/1*100+/' -e 's/千/1*1000+/' -e 's/万/1*10000+/' -e 's/\([0-9]\)1/\1/g' | bc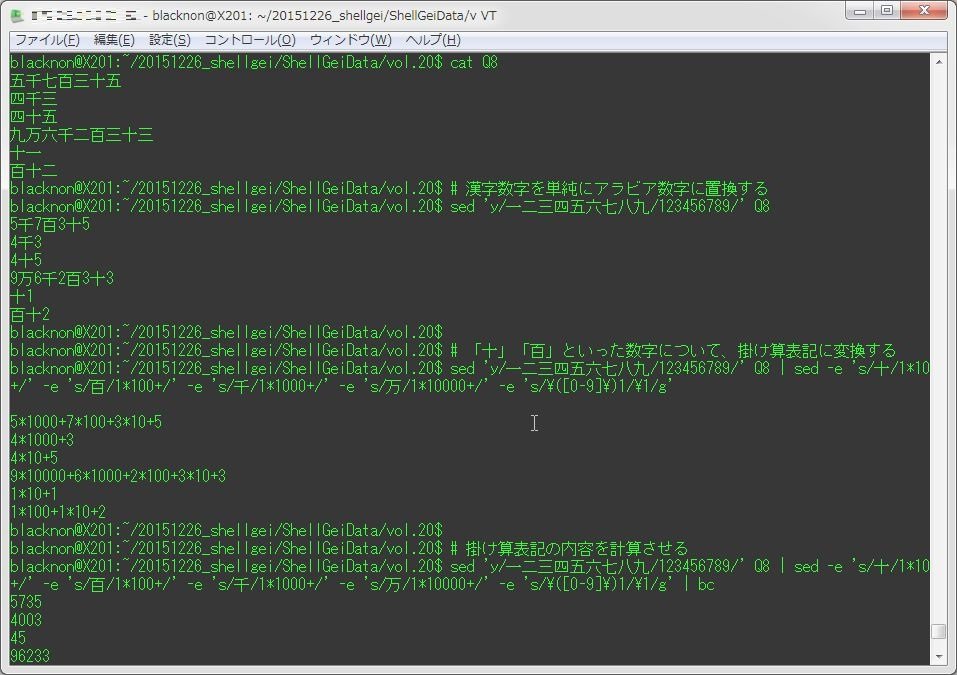
blacknon@X201:~/20151226_shellgei/ShellGeiData/vol.20$ cat Q8
五千七百三十五
四千三
四十五
九万六千二百三十三
十一
百十二
blacknon@X201:~/20151226_shellgei/ShellGeiData/vol.20$ # 漢字数字を単純にアラビア数字に置換する
blacknon@X201:~/20151226_shellgei/ShellGeiData/vol.20$ sed 'y/一二三四五六七八九/123456789/' Q8
5千7百3十5
4千3
4十5
9万6千2百3十3
十1
百十2
blacknon@X201:~/20151226_shellgei/ShellGeiData/vol.20$
blacknon@X201:~/20151226_shellgei/ShellGeiData/vol.20$ # 「十」「百」といった数字について、掛け算表記に変換する
blacknon@X201:~/20151226_shellgei/ShellGeiData/vol.20$ sed 'y/一二三四五六七八九/123456789/' Q8 | sed -e 's/十/1*10+/' -e 's/百/1*100+/' -e 's/千/1*1000+/' -e 's/万/1*10000+/' -e 's/\([0-9]\)1/\1/g'
5*1000+7*100+3*10+5
4*1000+3
4*10+5
9*10000+6*1000+2*100+3*10+3
1*10+1
1*100+1*10+2
blacknon@X201:~/20151226_shellgei/ShellGeiData/vol.20$
blacknon@X201:~/20151226_shellgei/ShellGeiData/vol.20$ # 掛け算表記の内容を計算させる
blacknon@X201:~/20151226_shellgei/ShellGeiData/vol.20$ sed 'y/一二三四五六七八九/123456789/' Q8 | sed -e 's/十/1*10+/' -e 's/百/1*100+/' -e 's/千/1*1000+/' -e 's/万/1*10000+/' -e 's/\([0-9]\)1/\1/g' | bc
5735
4003
45
96233
11
112とりあえず、復習としては以上だろうか。
う~ん…あんまり歯が立たなかったなぁ…
次回は、もう少し健闘したいと思う。

