")
だいぶ遅くなってしまったけど、第31回シェル芸勉強会に行ってきたのでその復習。今回は問題数がいつもより1問多く、9問出題されている。 問題・解答はこちら。 正直、今回はえらい難しかった気がする。あまり解けなかった。
事前に、問題用のデータを以下のコマンドでダウンロードしておく。
git clone https://github.com/ryuichiueda/ShellGeiData.gitQ1.
num.txtという数字が羅列されたファイルから、「1」の前の数字を削除するという問題。 改行は無視する必要があるので、ただ単純にsedで後方参照をすればいいというものではない。
模範解答では、前回の第30回の午前に扱われていたperlの正規表現でルックアラウンドアサーション(look-around assertions)を使って、行またぎでの置換をすることで対処している。 (参考:正規表現: 先読み・後読み言明 (look-around assertions) – CLARA ONLINE techblog)
cat num.txt | perl -0 -pe 's/.(\n)?(?=1)/\1/g'sedでやる場合だと、Perlの正規表現は使えないので拡張正規表現で対応する必要がある。
cat num.txt |sed -re 's/.(\n*1)/\1/g'ちなみにgrepではPerlの正規表現が使えるので、それを利用して削除対象箇所だけをハイライトさせることもできる。
cat num.txt | grep -zP '.(\n)?(?=1)'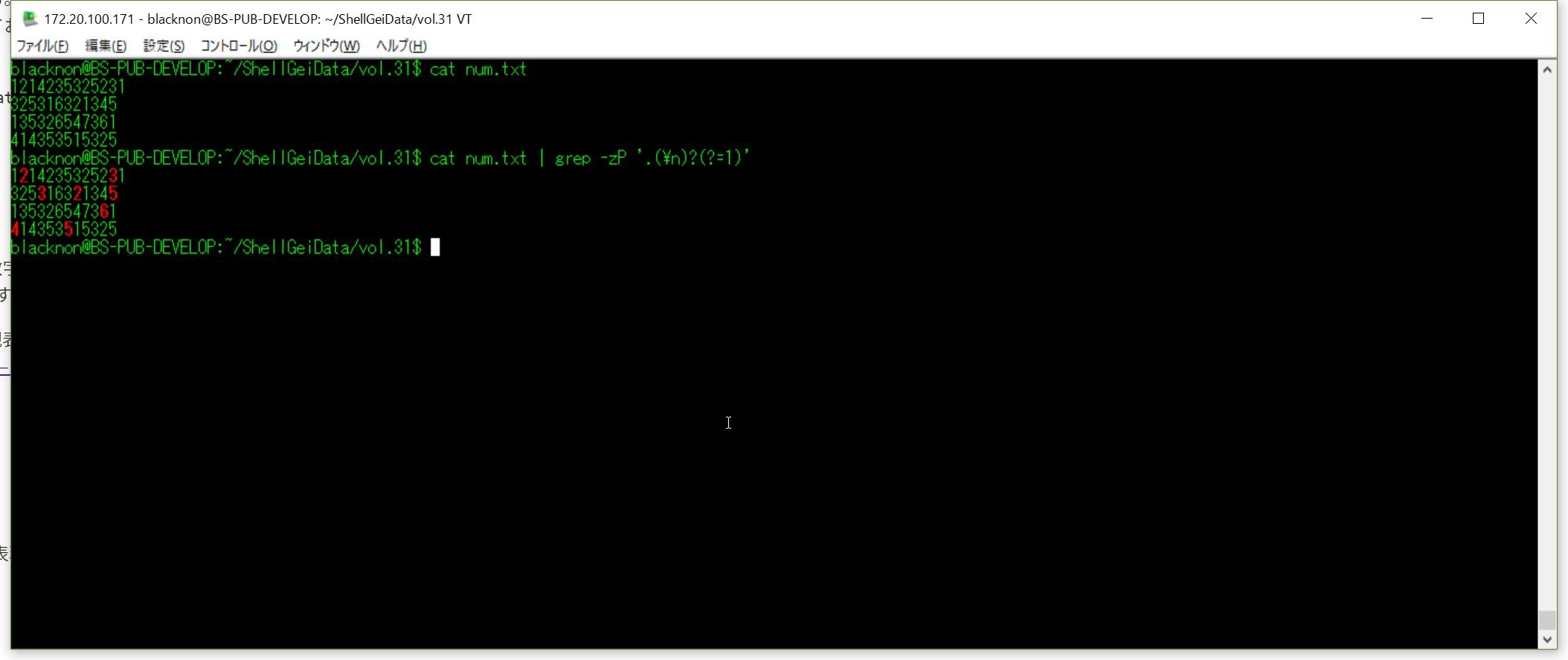
Q2.
indent.txtの内容から、偶数行のインデントを一個前の奇数行のものに合わせるという内容。 つまり、奇数行の時にインデント部分だけを取得して、奇数行偶数行の際にそれを利用してやればいいので、以下のように記述すればいい。 カンマで指定すると余計なスペースが入ってしまうので文字列結合をしている。
cat indent.txt | awk -F"*" 'NR%2!=0{i=$1}{print i"*"$2}'blacknon@BS-PUB-DEVELOP:~/ShellGeiData/vol.31$ cat indent.txt | awk -F"*" 'NR%2!=0{i=$1}{print i"*"$2}'
* aa
* bbb
* cccccc
* ddd
* eeeeeeeeee
* fff
* gggg
* hhhQ3.
横に並んでいる20行、20文字のアスタリスクの文字列で、行数が素数(ここでは1は素数ではないと仮定)の場合にその文字数の箇所だけ@に書き換わっている一覧を出力するという問題。 文字数のリピートはprintf(今回はawkのprintf)を使えばいいので、以下のようにすることで対応した。
※ @ebanさんより指摘を受けて修正している。awkのトコ、1だとNF=2の時に2行出てしまうわ…。
seq 1 20 | factor | awk 'NF==2{print gensub("*","@",$2,x)}NF!=2{print x}' x=$(printf *"%.s" {1..20})blacknon@BS-PUB-DEVELOP:~/ShellGeiData/vol.31$ seq 1 20 | factor | awk 'NF==2{print gensub("*","@",$2,x)}1{print x}' x=$(printf *"%.s" {1..20})
********************
*@******************
**@*****************
********************
****@***************
********************
******@*************
********************
********************
********************
**********@*********
********************
************@*******
********************
********************
********************
****************@***
********************
******************@*
********************Q4.
ASCIIコードだけを使って「おはようございます」という文字列を得るという問題。 UTF-8コードで記述したり、Base64にしたりといった方法もあるが、それだと面白くない。 なので、ローマ字読みで「ohayougozaimasu」と記述して、それを使ってGoogleサジェストから候補を取ってくるという方法を取った(awkのトコは決め打ちになってる)。
echo ohayougozaimasu | xargs -I@ curl -s 'http://suggestqueries.google.com/complete/search?output=toolbar&hl=ja&q=@&gl=ja' | nkf | awk -F'[" ]' '{print $6}'blacknon@BS-PUB-DEVELOP:~/ShellGeiData/vol.31$ echo ohayougozaimasu | xargs -I@ curl -s 'http://suggestqueries.google.com/complete/search?output=toolbar&hl=ja&q=@&gl=ja' | nkf
<!--?xml version="1.0"?-->
blacknon@BS-PUB-DEVELOP:~/ShellGeiData/vol.31$ echo ohayougozaimasu | xargs -I@ curl -s 'http://suggestqueries.google.com/complete/search?output=toolbar&hl=ja&q=@&gl=ja' | nkf | awk -F'[" ]' '{print $6}'
おはようございます
Q5.
2つの自然数の最小公倍数を求めるという問題。 この辺を参考にして考えたりもするが、ワンライナーだと短く書くのが厳しい。 で、Perlだったら「Math::BigInt」というライブラリが最初から入っている場合が多いので、これを利用して計算する。
echo | perl -lne 'use Math::BigInt;print Math::BigInt::blcm(18, 19)'blacknon@BS-PUB-DEVELOP:~/ShellGeiData/vol.31$ echo | perl -lne 'use Math::BigInt;print Math::BigInt::blcm(18, 19)'
342
blacknon@BS-PUB-DEVELOP:~/ShellGeiData/vol.31$ echo | perl -lne 'use Math::BigInt;print Math::BigInt::blcm(9,8)'
72
blacknon@BS-PUB-DEVELOP:~/ShellGeiData/vol.31$ echo | perl -lne 'use Math::BigInt;print Math::BigInt::blcm(9,11)'
99
blacknon@BS-PUB-DEVELOP:~/ShellGeiData/vol.31$ echo | perl -lne 'use Math::BigInt;print Math::BigInt::blcm(9,12)'
36Q6.
「echo あいうえお」から始めて「ぁぃぅぇぉ」(小さいやつ)を出力するという内容。 UTF-8の一覧(参考)を見ると、文字コードでみると1個違いというのがわかる。 なので、各文字を文字コードに変換して1を引き、また元に戻せばいい。
echo あいうえお | grep -o . | xargs -I@ bash -c 'printf @|xxd -p|printf %x $((0x$(cat) - 1))|xxd -r -p'blacknon@BS-PUB-DEVELOP:~/ShellGeiData/vol.31$ echo あいうえお | grep -o . | xargs -I@ bash -c 'printf @|xxd -p|printf %x $((0x$(cat) - 1))|xxd -r -p'
ぁぃぅぇぉQ7.
ピラミッド型のアニメーションを作るというお題。 この辺から力尽きてきたため、ちゃんと回答できず。 模範解答を元にした回答だけ貼っとく。
perl -E 'say " "x20," ^";for($i=1;$i<20;$i++){say " "x(20-$i),"/"," "x($i*2+1),"\\"}'|awk '{system("sleep 0.5");print}NR>20{exit(0)}'Q8.
用意されていた「sd.txt」というファイルで、半角を0.5文字、全角を1文字として各行5文字(割り切れない場合は4.5文字)で分割するという内容。 以下のように回答したが、模範解答と比べると微妙に出力結果が違った。
cat sd.txt|tr -d '\n'|sed 's/ /_/g;s/\B/ /g'|fold -s -w20|tr -d ' '|sed 's/_/ /g'blacknon@BS-PUB-DEVELOP:~/ShellGeiData/vol.31$ cat sd.txt|tr -d '\n'|sed 's/ /_/g;s/\B/ /g'|fold -s -w20|tr -d ' '|sed 's/_/ /g'
Software D
esignの「シ
ェル芸人か
らの挑戦
状」は絶好
調なんです
が、もうち
ょっとTwit
terで読ん
だ感想を述
べていただ
ければと。
blacknon@BS-PUB-DEVELOP:~/ShellGeiData/vol.31$
blacknon@BS-PUB-DEVELOP:~/ShellGeiData/vol.31$ cat sd.txt | grep -o . |
> LANG=C awk '{if(/[[:print:]]/){print 1,$1}else{print 2,$1}}' |
> awk '{a+=$1;if(a>10){print "";a=$1}}{printf $2}NF==1{printf " "}' |
> awk 1
Software D
esignの「
シェル芸人
からの挑戦
状」は絶好
調なんです
が、もうち
ょっとTwit
terで読ん
だ感想を述
べていただ
ければと。Q9.
元素の周期表csvファイルを生成するという問題。 例では、生成元となるのはhtmlテーブルとなっているため、それをうまいことCSVに変換するという内容。 結構ゴリ押しでやらないといけないようで、ちょっと疲れてきたので模範解答をそのまま貼っとく。
w3m http://www.gadgety.net/shin/trivia/ptable/ -dump |
grep -E '(H|Li|Na|K|Rb|Cs|Fr|La|Ac)' |
awk 'NR<=9' | sed 's/ラ/ L/' | sed 's/ /@@ |/g' |
sed 's/ /@@ /g' | tr -d '│|' | sed 's/^ *//' |
sed 's/ */,/g' | tr -d @ | sed -e 's/,La/\nL&/' -e 's/,Ac/A&/' |
sed 's/^,//'blacknon@BS-PUB-DEVELOP:~/ShellGeiData/vol.31$ w3m http://www.gadgety.net/shin/trivia/ptable/ -dump |
> grep -E '(H|Li|Na|K|Rb|Cs|Fr|La|Ac)' |
> awk 'NR<=9' | sed 's/ラ/ L/' | sed 's/ /@@ |/g' | > sed 's/ /@@ /g' | tr -d 'x|' | sed 's/^ *//' |
> sed 's/ */,/g' | tr -d @ | sed -e 's/,La/\nL&/' -e 's/,Ac/A&/' |
> sed 's/^,//'
H,,,,,,,,,,,,,,,,,He,
Li,Be,,,,,,,,,,,B,C,N,O,F,Ne,
Na,Mg,,,,,,,,,,,Al,Si,P,S,Cl,Ar,
K,Ca,Sc,Ti,V,Cr,Mn,Fe,Co,Ni,Cu,Zn,Ga,Ge,As,Se,Br,Kr,
Rb,Sr,Y,Zr,Nb,Mo,Tc,Ru,Rh,Pd,Ag,Cd,In,Sn,Sb,Te,I,Xe,
Cs,Ba,L,Hf,Ta,W,Re,Os,Ir,Pt,Au,Hg,Tl,Pb,Bi,Po,At,Rn,
Fr,Ra,A,Rf,Db,Sg,Bh,Hs,Mt,Ds,Rg,Cn,Nh,Fl,Mc,Lv,Ts,Og,
L,La,Ce,Pr,Nd,Pm,Sm,Eu,Gd,Tb,Dy,Ho,Er,Tm,Yb,Lu,,
A,Ac,Th,Pa,U,Np,Pu,Am,Cm,Bk,Cf,Es,Fm,Md,No,Lr,,
