
ここのところ、仕事でJSONをいじる際にjqコマンドで触る事が多くなったので、使ってて便利だと思った使い方についてをまとめてみることにした。
1.読みやすいよう整形する
jqコマンドをただ通すだけで、整形されてないJSONファイルを読みやすいように整形して出力させることができる。
jq . 対象ファイル
[root@BS-PUB-CENT7-02 ~]# cat /tmp/sample0.json
[{"id":"0001","name":"test001","value":112,"group1":{"subg01":[{"id":"1001","type":"type001"},{"id":"1004","type":"type002"}]},"group2":[{"id":"5001","type":"None"},{"id":"5003","type":"type053"},{"id":"5004","type":"type054"}]},{"id":"0002","name":"test002","value":954,"group1":{"subg01":[{"id":"1021","type":"type101"},{"id":"1054","type":"type052"}]},"group2":[{"id":"5001","type":"None"},{"id":"5004","type":"type054"}]}][root@BS-PUB-CENT7-02 ~]#
[root@BS-PUB-CENT7-02 ~]# jq . /tmp/sample0.json
[
{
"id": "0001",
"name": "test001",
"value": 112,
"group1": {
"subg01": [
{
"id": "1001",
"type": "type001"
},
{
"id": "1004",
"type": "type002"
}
]
},
"group2": [
{
"id": "5001",
"type": "None"
},
{
"id": "5003",
"type": "type053"
},
{
"id": "5004",
"type": "type054"
}
]
},
{
"id": "0002",
"name": "test002",
"value": 954,
"group1": {
"subg01": [
{
"id": "1021",
"type": "type101"
},
{
"id": "1054",
"type": "type052"
}
]
},
"group2": [
{
"id": "5001",
"type": "None"
},
{
"id": "5004",
"type": "type054"
}
]
}
]長いJSONファイルの場合だと長くなるので、そういった時は「-c」をつけると良いだろう。
[root@BS-PUB-CENT7-02 ~]# jq -c . /tmp/sample0.json
[{"id":"0001","name":"test001","value":112,"group1":{"subg01":[{"id":"1001","type":"type001"},{"id":"1004","type":"type002"}]},"group2":[{"id":"5001","type":"None"},{"id":"5003","type":"type053"},{"id":"5004","type":"type054"}]},{"id":"0002","name":"test002","value":954,"group1":{"subg01":[{"id":"1021","type":"type101"},{"id":"1054","type":"type052"}]},"group2":[{"id":"5001","type":"None"},{"id":"5004","type":"type054"}]}]2.値のみを抽出する
jqコマンドでは、値を抽出したいキーを指定することで、その値のみ列挙させる事ができる。
jq 'キー' 対象ファイル[root@BS-PUB-CENT7-02 ~]# # 最上位のidだけ抽出
[root@BS-PUB-CENT7-02 ~]# cat /tmp/sample1.json | grep id
"id": "0001",
{ "id": "1001", "type": "type001" },
{ "id": "1004", "type": "type002" }
{ "id": "5001", "type": "None" },
{ "id": "5003", "type": "type053" },
{ "id": "5004", "type": "type054" }
"id": "0002",
{ "id": "1021", "type": "type101" },
{ "id": "1054", "type": "type052" }
{ "id": "5001", "type": "None" },
{ "id": "5004", "type": "type054" }
[root@BS-PUB-CENT7-02 ~]# jq '.[].id' /tmp/sample0.json
"0001"
"0002"
[root@BS-PUB-CENT7-02 ~]# # 配列を指定してその配下のKey/Valueを全て抽出
[root@BS-PUB-CENT7-02 ~]# jq . /tmp/sample1.json
[
{
"id": "0001",
"name": "test001",
"value": 112,
"group1": {
"subg01": [
{
"id": "1001",
"type": "type001"
},
{
"id": "1004",
"type": "type002"
}
]
},
"group2": [
{
"id": "5001",
"type": "None"
},
{
"id": "5003",
"type": "type053"
},
{
"id": "5004",
"type": "type054"
}
]
},
{
"id": "0002",
"name": "test002",
"value": 954,
"group1": {
"subg01": [
{
"id": "1021",
"type": "type101"
},
{
"id": "1054",
"type": "type052"
}
]
},
"group2": [
{
"id": "5001",
"type": "None"
},
{
"id": "5004",
"type": "type054"
}
]
}
]
[root@BS-PUB-CENT7-02 ~]# jq -c '.[].group1.subg01' /tmp/sample0.json
[{"id":"1001","type":"type001"},{"id":"1004","type":"type002"}]
[{"id":"1021","type":"type101"},{"id":"1054","type":"type052"}]なお、配列内の値のみを抽出する場合は、以下のように「配列名[].キー名」と記述することで指定が可能となる。
[root@BS-PUB-CENT7-02 ~]# jq '.[].group1.subg01[].id' /tmp/sample0.json
"1001"
"1004"
"1021"
"1054"3.条件に合わせて抽出を行う
'select(キー名 条件 値)'といった指定を行う事で、条件に合致した配列やキーを取得することができる。
なお、検索対象が配列の場合、select前に配列の殻割りをしないとトップレベルで出てきてしまうので注意。
[root@BS-PUB-CENT7-02 ~]# jq -c '.[].group1.subg01[] | select(.id == "1021")' /tmp/sample1.json
{"id":"1021","type":"type101"}
[root@BS-PUB-CENT7-02 ~]# jq '.[] | select(.group1.subg01[].id == "1021")' /tmp/sample1.json
{
"id": "0002",
"name": "test002",
"value": 954,
"group1": {
"subg01": [
{
"id": "1021",
"type": "type101"
},
{
"id": "1054",
"type": "type052"
}
]
},
"group2": [
{
"id": "5001",
"type": "None"
},
{
"id": "5004",
"type": "type054"
}
]
}なお、このselectでは「>」「<」「!=」といった一般的な演算子が使える。
状況に合わせて使い分けよう。
4.「and」「or」「not」で指定する
jqコマンドでは、「and」「or」「not」での条件指定にも対応している。
select内で条件指定することで対象の配列の情報を抽出できる(そのまま使うと、True/Falseが返ってくる)。
[root@BS-PUB-CENT7-02 ~]# jq -c '.[] | select((.value >= 1000 ) and (.type == "B"))' /tmp/sample3.json
{"id":2,"value":24365,"type":"B"}
{"id":6,"value":54750,"type":"B"}
{"id":7,"value":3547,"type":"B"}
[root@BS-PUB-CENT7-02 ~]# jq -c '.[] | select((.value >= 1000 ) or (.type == "B"))' /tmp/sample3.json
{"id":1,"value":1243,"type":"A"}
{"id":2,"value":24365,"type":"B"}
{"id":3,"value":201,"type":"B"}
{"id":4,"value":5465,"type":"C"}
{"id":6,"value":54750,"type":"B"}
{"id":7,"value":3547,"type":"B"}
[root@BS-PUB-CENT7-02 ~]# jq -c '.[] | select((.value >= 1000 ) and (.type == "B") | not)' /tmp/sample3.json
{"id":1,"value":1243,"type":"A"}
{"id":3,"value":201,"type":"B"}
{"id":4,"value":5465,"type":"C"}
{"id":5,"value":24,"type":"A"}5.特定のキー・値を持つ配列の値を置換orキーを追加する
以下のようにコマンドを実行することで、指定したキーと値を持つ配列において、キーの値を置き換えたりキーを追加したりすることが出来る。
jq '(.[] | select(.条件となるキー名 == "キーの値") | 書き換える・追加するキー名) |= "キーの値"' 対象のJSONファイル[root@BS-PUB-CENT7-02 ~]# # 「.id」が0001の配列の「.name」を置き換える
[root@BS-PUB-CENT7-02 ~]# jq '.[] | select(.id == "0001")' /tmp/sample1.json
{
"id": "0001",
"name": "test001",
"value": 112,
"group1": {
"subg01": [
{
"id": "1001",
"type": "type001"
},
{
"id": "1004",
"type": "type002"
}
]
},
"group2": [
{
"id": "5001",
"type": "None"
},
{
"id": "5003",
"type": "type053"
},
{
"id": "5004",
"type": "type054"
}
]
}
[root@BS-PUB-CENT7-02 ~]# jq '(.[] | select(.id == "0001") | .name)="test999"' /tmp/sample1.json | jq '.[] | select(.id == "0001")'
{
"id": "0001",
"name": "test999",
"value": 112,
"group1": {
"subg01": [
{
"id": "1001",
"type": "type001"
},
{
"id": "1004",
"type": "type002"
}
]
},
"group2": [
{
"id": "5001",
"type": "None"
},
{
"id": "5003",
"type": "type053"
},
{
"id": "5004",
"type": "type054"
}
]
}なお、配列内のキーの値に応じて書き換えを行う場合、以下のようにselect前に配列の殻割りをしてやる必要がある。
[root@BS-PUB-CENT7-02 ~]# jq . /tmp/sample1.json
[
{
"id": "0001",
"name": "test001",
"value": 112,
"group1": {
"subg01": [
{
"id": "1001",
"type": "type001"
},
{
"id": "1004",
"type": "type002"
}
]
},
"group2": [
{
"id": "5001",
"type": "None"
},
{
"id": "5003",
"type": "type053"
},
{
"id": "5004",
"type": "type054"
}
]
},
{
"id": "0002",
"name": "test002",
"value": 954,
"group1": {
"subg01": [
{
"id": "1021",
"type": "type101"
},
{
"id": "1054",
"type": "type052"
}
]
},
"group2": [
{
"id": "5001",
"type": "None"
},
{
"id": "5004",
"type": "type054"
}
]
}
]
[root@BS-PUB-CENT7-02 ~]# jq '(.[] | .group1.subg01[] | select(.[] == "1001") | .type)|= "type111" ' /tmp/sample1.json
[
{
"id": "0001",
"name": "test001",
"value": 112,
"group1": {
"subg01": [
{
"id": "1001",
"type": "type111"
},
{
"id": "1004",
"type": "type002"
}
]
},
"group2": [
{
"id": "5001",
"type": "None"
},
{
"id": "5003",
"type": "type053"
},
{
"id": "5004",
"type": "type054"
}
]
},
{
"id": "0002",
"name": "test002",
"value": 954,
"group1": {
"subg01": [
{
"id": "1021",
"type": "type101"
},
{
"id": "1054",
"type": "type052"
}
]
},
"group2": [
{
"id": "5001",
"type": "None"
},
{
"id": "5004",
"type": "type054"
}
]
}
]
これを応用してやれば、指定した条件の配列の場合、さらに任意の配列を追加できる(日本語がややこしくなってきたな…)。
[root@BS-PUB-CENT7-02 ~]# jq '(.[] | .group1.subg01[] | select(.[] == "1001")| .aaa)|=[1,2,3]' /tmp/sample1.json | jq .[].group1.subg01
[
{
"id": "1001",
"type": "type001",
"aaa": [
1,
2,
3
]
},
{
"id": "1004",
"type": "type002"
}
]
[
{
"id": "1021",
"type": "type101"
},
{
"id": "1054",
"type": "type052"
}
]6.特定の配列の値に合算や除算等を行う
上の応用。jqコマンドでは「|=」の他、「+=」, 「-=」, 「*=」, 「/=」といった演算子がある。
これを利用することで、特定の配列の値に対して合算や文字列の結合といった処理を行う事も出来る。
(以下の例では、JSONファイルが全部出てくるとうざったいので編集したとこに絞って出力している。また、今回は記述しないけど「%=」で割り算のあまりが、「//=」で値やキーが無い時のデフォルト値を定義できる。)
[root@BS-PUB-CENT7-02 ~]# # 値の結合(数字の場合は加算)
[root@BS-PUB-CENT7-02 ~]# jq '(.[] | .group1.subg01[] | select(.[] == "1001")| .type)+="_test1111"' /tmp/sample1.json | jq .[].group1.subg01
[
{
"id": "1001",
"type": "type001_test1111"
},
{
"id": "1004",
"type": "type002"
}
]
[
{
"id": "1021",
"type": "type101"
},
{
"id": "1054",
"type": "type052"
}
]
[root@BS-PUB-CENT7-02 ~]# jq '.[] | select(.id == "0001") | .value' /tmp/sample1.json
112
[root@BS-PUB-CENT7-02 ~]# jq '(.[] | select(.id == "0001")| .value)+=100' /tmp/sample1.json | jq '.[] | select(.id == "0001") | .value'
212
[root@BS-PUB-CENT7-02 ~]# jq '(.[] | select(.id == "0001")| .value)-=100' /tmp/sample1.json | jq '.[] | select(.id == "0001") | .value'
12
[root@BS-PUB-CENT7-02 ~]# jq '(.[] | select(.id == "0001")| .value)*=100' /tmp/sample1.json | jq '.[] | select(.id == "0001") | .value'
11200
[root@BS-PUB-CENT7-02 ~]# jq '(.[] | select(.id == "0001")| .value)/=100' /tmp/sample1.json | jq '.[] | select(.id == "0001") | .value'
1.127.集計を行う
jqコマンドでは、当然JSONファイルでの集計といったことも出来る。
以下、いくつか思いついた、使った集計処理
条件に合致したキー数の数を取得する
'length'を用いる事で、配列内のキー数の数をカウントすることが出来る。
[root@BS-PUB-CENT7-02 ~]# # 指定した配列内のキー数を取得する
[root@BS-PUB-CENT7-02 ~]# jq -c '.[] | select(.id == "0002") | .group1.subg01[1]' /tmp/sample1.json
{"id":"1054","type":"type052"}
[root@BS-PUB-CENT7-02 ~]# jq '.[] | select(.id == "0002") | .group1.subg01[1] | length' /tmp/sample1.json
2
[root@BS-PUB-CENT7-02 ~]#
[root@BS-PUB-CENT7-02 ~]# # 配列でないキーの数をカウントしたい場合は、length前の抽出文を[]で囲って配列として扱わせる
[root@BS-PUB-CENT7-02 ~]# jq '.[] | select((.value >= 1000 ) and (.type == "B") | not) | .id' /tmp/sample3.json
1
3
4
5
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | select((.value >= 1000 ) and (.type == "B") | not) | .id]' /tmp/sample3.json
[1,3,4,5]
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | select((.value >= 1000 ) and (.type == "B") | not) | .id] | length' /tmp/sample3.json
4条件に合致したキーの値を合計する
'add'で、配列内の値を合計することが出来る。
[root@BS-PUB-CENT7-02 ~]# # 集計したい条件を指定
[root@BS-PUB-CENT7-02 ~]# jq '.[] | select((.value >= 1000 ) and (.type == "B")) | .value' /tmp/sample3.json
24365
54750
3547
[root@BS-PUB-CENT7-02 ~]# # 1回配列にする
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | select((.value >= 1000 ) and (.type == "B")) | .value]' /tmp/sample3.json
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | select((.value >= 1000 ) and (.type == "B")) | .value]' /tmp/sample3.json
[24365,54750,3547]
[root@BS-PUB-CENT7-02 ~]# # 合計値を取得
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | select((.value >= 1000 ) and (.type == "B")) | .value] | add' /tmp/sample3.json
82662平均を求める
上の要領で平均を求める事もできる。
[root@BS-PUB-CENT7-02 ~]# # 合計(add)個数(length)を求める
[root@BS-PUB-CENT7-02 ~]# jq '[.[] | select((.value >= 1000 ) and (.type == "B")) | .value] | add,length' /tmp/sample3.json
82662
3
[root@BS-PUB-CENT7-02 ~]#
[root@BS-PUB-CENT7-02 ~]# # 合計(add)/個数(length)で平均を求める
[root@BS-PUB-CENT7-02 ~]# jq '[.[] | select((.value >= 1000 ) and (.type == "B")) | .value] | add/length' /tmp/sample3.json
27554</pre>
## 各要素ごとの数をカウントする
キーごとの数をカウントする場合、以下のようにgroup_by(後述)でグループ分けをしてやれば良い。
※その他、各要素ごとの合計や平均・最大最小値などについてはリンク先を参照してもらいたい。
```shell
[root@BS-PUB-CENT7-02 ~]# # 「type」のそれぞれの数を求めたいとする
[root@BS-PUB-CENT7-02 ~]# jq -c '.[] | .type' /tmp/sample3.json
"A"
"B"
"B"
"C"
"A"
"B"
"B"
[root@BS-PUB-CENT7-02 ~]# # 一度配列にしてやる必要がある
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | .type]' /tmp/sample3.json
["A","B","B","C","A","B","B"]
[root@BS-PUB-CENT7-02 ~]# # 「group_by」で値ごとに配列を分ける
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | .type] | group_by(.)' /tmp/sample3.json
[["A","A"],["B","B","B","B"],["C"]]
[root@BS-PUB-CENT7-02 ~]# # mapで配列ごとにカウントする
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | .type] | group_by(.) | map({(.[0]): length})' /tmp/sample3.json
[{"A":2},{"B":4},{"C":1}]
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | .type] | group_by(.) | map({(.[0]): length}) | add' /tmp/sample3.json
{"A":2,"B":4,"C":1}8.最大値・最小値を抽出する
jqでは、「max」「min」を用いる事で配列内の最大値、最小値を求めることも出来る。
[root@BS-PUB-CENT7-02 ~]# # 配列内の最大・最小値を求める
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | .value]' /tmp/sample3.json
[1243,24365,201,5465,24,54750,3547]
[root@BS-PUB-CENT7-02 ~]# jq '[.[] | .value] | max' /tmp/sample3.json
54750
[root@BS-PUB-CENT7-02 ~]# jq '[.[] | .value] | min' /tmp/sample3.json
24
[root@BS-PUB-CENT7-02 ~]#
[root@BS-PUB-CENT7-02 ~]# # 最大・最小値を持つ配列を抽出する
[root@BS-PUB-CENT7-02 ~]# jq -c 'max_by(.value)' /tmp/sample3.json
{"id":6,"value":54750,"type":"B"}
[root@BS-PUB-CENT7-02 ~]# jq -c 'min_by(.value)' /tmp/sample3.json
{"id":5,"value":24,"type":"A"}9.キーの値ごとにソートする
「sort」「sort_by」で、キーの値ごとに出力内容をソートできる。
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | .value]' /tmp/sample3.json
[1243,24365,201,5465,24,54750,3547]
[root@BS-PUB-CENT7-02 ~]# # 「sort」で配列内をソートする
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | .value] | sort' /tmp/sample3.json
[24,201,1243,3547,5465,24365,54750]
[root@BS-PUB-CENT7-02 ~]# # 「reverse」で逆順にする
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | .value] | sort | reverse' /tmp/sample3.json
[54750,24365,5465,3547,1243,201,24]
[root@BS-PUB-CENT7-02 ~]#
[root@BS-PUB-CENT7-02 ~]# # 「sort_by」で指定された値にそって配列をソートする
[root@BS-PUB-CENT7-02 ~]# jq -c '.[]' /tmp/sample3.json
{"id":1,"value":1243,"type":"A"}
{"id":2,"value":24365,"type":"B"}
{"id":3,"value":201,"type":"B"}
{"id":4,"value":5465,"type":"C"}
{"id":5,"value":24,"type":"A"}
{"id":6,"value":54750,"type":"B"}
{"id":7,"value":3547,"type":"B"}
[root@BS-PUB-CENT7-02 ~]# jq -c 'sort_by(.value)|.[]' /tmp/sample3.json
{"id":5,"value":24,"type":"A"}
{"id":3,"value":201,"type":"B"}
{"id":1,"value":1243,"type":"A"}
{"id":7,"value":3547,"type":"B"}
{"id":4,"value":5465,"type":"C"}
{"id":2,"value":24365,"type":"B"}
{"id":6,"value":54750,"type":"B"}
[root@BS-PUB-CENT7-02 ~]# jq -c 'sort_by(.value) | reverse | .[]' /tmp/sample3.json
{"id":6,"value":54750,"type":"B"}
{"id":2,"value":24365,"type":"B"}
{"id":4,"value":5465,"type":"C"}
{"id":7,"value":3547,"type":"B"}
{"id":1,"value":1243,"type":"A"}
{"id":3,"value":201,"type":"B"}
{"id":5,"value":24,"type":"A"}10.ユニークな値を抽出する
「unique」「unique_by」を利用することで、ユニークな値のみに絞って出力させることが出来る。
[root@BS-PUB-CENT7-02 ~]# jq -c '.[].type' /tmp/sample3.json
"A"
"B"
"B"
"C"
"A"
"B"
"B"
[root@BS-PUB-CENT7-02 ~]# # uniqueは同じ配列内に入れてやる必要があるので加工
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[].type]' /tmp/sample3.json
["A","B","B","C","A","B","B"]
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[].type] | unique' /tmp/sample3.json
["A","B","C"]
[root@BS-PUB-CENT7-02 ~]#
[root@BS-PUB-CENT7-02 ~]# # unique_byで指定した値の配列を一つだけ抽出する(抽出される配列はソート順で最初に出てきたやつが抽出される)
[root@BS-PUB-CENT7-02 ~]# jq -c 'sort_by(.value)|.[] ' /tmp/sample3.json
{"id":5,"value":24,"type":"A"}
{"id":3,"value":201,"type":"B"}
{"id":1,"value":1243,"type":"A"}
{"id":7,"value":3547,"type":"B"}
{"id":4,"value":5465,"type":"C"}
{"id":2,"value":24365,"type":"B"}
{"id":6,"value":54750,"type":"B"}
[root@BS-PUB-CENT7-02 ~]# jq -c 'sort_by(.value)' /tmp/sample3.json
[{"id":5,"value":24,"type":"A"},{"id":3,"value":201,"type":"B"},{"id":1,"value":1243,"type":"A"},{"id":7,"value":3547,"type":"B"},{"id":4,"value":5465,"type":"C"},{"id":2,"value":24365,"type":"B"},{"id":6,"value":54750,"type":"B"}]
[root@BS-PUB-CENT7-02 ~]# jq -c 'sort_by(.value) | unique_by(.type) ' /tmp/sample3.json
[{"id":5,"value":24,"type":"A"},{"id":3,"value":201,"type":"B"},{"id":4,"value":5465,"type":"C"}]
[root@BS-PUB-CENT7-02 ~]# jq -c 'sort_by(.value)| reverse |.[] ' /tmp/sample3.json
{"id":6,"value":54750,"type":"B"}
{"id":2,"value":24365,"type":"B"}
{"id":4,"value":5465,"type":"C"}
{"id":7,"value":3547,"type":"B"}
{"id":1,"value":1243,"type":"A"}
{"id":3,"value":201,"type":"B"}
{"id":5,"value":24,"type":"A"}
[root@BS-PUB-CENT7-02 ~]# jq -c 'sort_by(.value)| reverse' /tmp/sample3.json
[{"id":6,"value":54750,"type":"B"},{"id":2,"value":24365,"type":"B"},{"id":4,"value":5465,"type":"C"},{"id":7,"value":3547,"type":"B"},{"id":1,"value":1243,"type":"A"},{"id":3,"value":201,"type":"B"},{"id":5,"value":24,"type":"A"}]
[root@BS-PUB-CENT7-02 ~]# jq -c 'sort_by(.value)| reverse | unique_by(.type) ' /tmp/sample3.json
[{"id":1,"value":1243,"type":"A"},{"id":6,"value":54750,"type":"B"},{"id":4,"value":5465,"type":"C"}]11.値に応じてグループを分ける
集計処理のトコでも少し触れているが、jqコマンドでは「group_by」で指定したキーで配列をグループ分けさせることが出来る。
[root@BS-PUB-CENT7-02 ~]# jq -c 'group_by(.type)' /tmp/sample3.json -e
[[{"id":1,"value":1243,"type":"A"},{"id":5,"value":24,"type":"A"}],[{"id":2,"value":24365,"type":"B"},{"id":3,"value":201,"type":"B"},{"id":6,"value":54750,"type":"B"},{"id":7,"value":3547,"type":"B"}],[{"id":4,"value":5465,"type":"C"}]]
[root@BS-PUB-CENT7-02 ~]# # 分かりにくいので少し分解
[root@BS-PUB-CENT7-02 ~]# jq -c 'group_by(.type)' /tmp/sample3.json -e | sed -e 's/\[/\n\[/g' -e 's/]]/]\n]/g' | sed --quiet '2,$p'
[
[{"id":1,"value":1243,"type":"A"},{"id":5,"value":24,"type":"A"}],
[{"id":2,"value":24365,"type":"B"},{"id":3,"value":201,"type":"B"},{"id":6,"value":54750,"type":"B"},{"id":7,"value":3547,"type":"B"}],
[{"id":4,"value":5465,"type":"C"}]
]12.デフォルトの値を定める
jqコマンドでは、代替演算子として「// デフォルト値」といった指定方法が用意されている。
これを利用することで、もし抽出したい値がNullだった場合にはそのデフォルト値が出力される。
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | .type] | group_by(.) | map({(.[0]): length}) | add' /tmp/sample3.json
{"A":2,"B":4,"C":1}
[root@BS-PUB-CENT7-02 ~]#
[root@BS-PUB-CENT7-02 ~]# # Aの値を取得する
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | .type] | group_by(.) | map({(.[0]): length}) | add | ."A" // 150' /tmp/sample3.json
2
[root@BS-PUB-CENT7-02 ~]# # D(存在しないキー)の値を取得する
[root@BS-PUB-CENT7-02 ~]# jq -c '[.[] | .type] | group_by(.) | map({(.[0]): length}) | add | ."D" // 150' /tmp/sample3.json
15013.ダブルクォーテーションを出力しない
jqコマンドでは、デフォルトでは文字列は「"(ダブルクォーテーション)」で囲って出力するようになっている。
これを取っ払うには、「-r」オプションを付与する。
[root@BS-PUB-CENT7-02 ~]# jq -c '.[].name' /tmp/sample1.json
"test001"
"test002"
[root@BS-PUB-CENT7-02 ~]# jq -r -c '.[].name' /tmp/sample1.json
test001
test00214.配列内の値でhead/tail相当の処理を行う
抽出時に「[]」内で指定してやることで、配列内の指定した範囲の値を取得することができる。
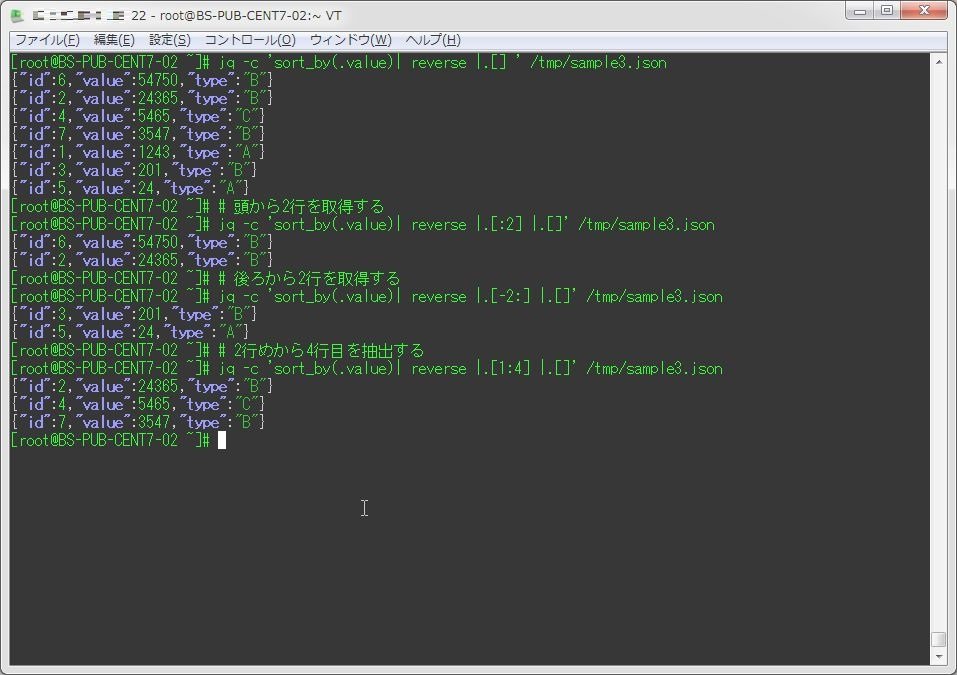
[root@BS-PUB-CENT7-02 ~]# jq -c 'sort_by(.value)| reverse |.[] ' /tmp/sample3.json
{"id":6,"value":54750,"type":"B"}
{"id":2,"value":24365,"type":"B"}
{"id":4,"value":5465,"type":"C"}
{"id":7,"value":3547,"type":"B"}
{"id":1,"value":1243,"type":"A"}
{"id":3,"value":201,"type":"B"}
{"id":5,"value":24,"type":"A"}
[root@BS-PUB-CENT7-02 ~]# # 頭から2行を取得する
[root@BS-PUB-CENT7-02 ~]# jq -c 'sort_by(.value)| reverse |.[:2] |.[]' /tmp/sample3.json
{"id":6,"value":54750,"type":"B"}
{"id":2,"value":24365,"type":"B"}
[root@BS-PUB-CENT7-02 ~]# # 後ろから2行を取得する
[root@BS-PUB-CENT7-02 ~]# jq -c 'sort_by(.value)| reverse |.[-2:] |.[]' /tmp/sample3.json
{"id":3,"value":201,"type":"B"}
{"id":5,"value":24,"type":"A"}
[root@BS-PUB-CENT7-02 ~]# # 2行めから4行目を抽出する
[root@BS-PUB-CENT7-02 ~]# jq -c 'sort_by(.value)| reverse |.[1:4] |.[]' /tmp/sample3.json
{"id":2,"value":24365,"type":"B"}
{"id":4,"value":5465,"type":"C"}
{"id":7,"value":3547,"type":"B"}15.置換をする
jqコマンドのバージョンが1.5以降である必要があるのだが、jqコマンド内で'gsub("置換前";"置換後")'として指定することで、置換を行う事が出来る。
[root@BS-PUB-CENT7-01 ~]# jq -c '.[]' /tmp/sample3.json
{"id":1,"value":1243,"type":"A"}
{"id":2,"value":24365,"type":"B"}
{"id":3,"value":201,"type":"B"}
{"id":4,"value":5465,"type":"C"}
{"id":5,"value":24,"type":"A"}
{"id":6,"value":54750,"type":"B"}
{"id":7,"value":3547,"type":"B"}
[root@BS-PUB-CENT7-01 ~]# jq -c '.[] | .type' /tmp/sample3.json
"A"
"B"
"B"
"C"
"A"
"B"
"B"
[root@BS-PUB-CENT7-01 ~]# jq -c '.[] | .type | gsub("B";"DDD")' /tmp/sample3.json
"A"
"DDD"
"DDD"
"C"
"A"
"DDD"
"DDD"
[root@BS-PUB-CENT7-01 ~]# jq -c '.[].name' /tmp/sample1.json
"test001"
"test002"
[root@BS-PUB-CENT7-01 ~]# jq -c '.[].name | gsub("test";"AAA")' /tmp/sample1.json
"AAA001"
"AAA002"16.JSONからCSVに変換する
JSONからCSVに切り替える場合は、行単位で配列に入れたJSONファイルを@csvに渡してやれば良い。
[root@BS-PUB-CENT7-01 ~]# jq -r -c '.[]' /tmp/sample3.json
{"id":1,"value":1243,"type":"A"}
{"id":2,"value":24365,"type":"B"}
{"id":3,"value":201,"type":"B"}
{"id":4,"value":5465,"type":"C"}
{"id":5,"value":24,"type":"A"}
{"id":6,"value":54750,"type":"B"}
{"id":7,"value":3547,"type":"B"}
[root@BS-PUB-CENT7-01 ~]# # 値のみを配列に入れる
[root@BS-PUB-CENT7-01 ~]# jq -r -c '.[] | [.id,.value,.type]' /tmp/sample3.json
[1,1243,"A"]
[2,24365,"B"]
[3,201,"B"]
[4,5465,"C"]
[5,24,"A"]
[6,54750,"B"]
[7,3547,"B"]
[root@BS-PUB-CENT7-01 ~]# # @csvに渡す
[root@BS-PUB-CENT7-01 ~]# jq -r -c '.[] | [.id,.value,.type] | @csv' /tmp/sample3.json
1,1243,"A"
2,24365,"B"
3,201,"B"
4,5465,"C"
5,24,"A"
6,54750,"B"
7,3547,"B"
[root@BS-PUB-CENT7-01 ~]# # ヘッダーを付けてやる(「[ .[] | keys ] | unique | .[]」でキー名だけ取得できる)
[root@BS-PUB-CENT7-01 ~]# jq -r -c '([ .[] | keys ] | unique | .[]),(.[] | [.id,.value,.type]) | @csv' /tmp/sample3.json
"id","type","value"
1,1243,"A"
2,24365,"B"
3,201,"B"
4,5465,"C"
5,24,"A"
6,54750,"B"
7,3547,"B"17.CSVからJSONに変換する
JSONからCSVに変換するのは結構簡単だったと思うが、CSVからJSONに切り替えるのは結構面倒くさい。
以下、実際に変換した際の例。
[root@BS-PUB-CENT7-01 ~]# cat /tmp/sample3.csv
1,1243,"A"
2,24365,"B"
3,201,"B"
4,5465,"C"
5,24,"A"
6,54750,"B"
7,3547,"B"
[root@BS-PUB-CENT7-01 ~]# # 不要なダブルクォーテーションを置換する
[root@BS-PUB-CENT7-01 ~]# jq -c --slurp -rR 'gsub("\"";"")' /tmp/sample3.csv
1,1243,A
2,24365,B
3,201,B
4,5465,C
5,24,A
6,54750,B
7,3547,B
[root@BS-PUB-CENT7-01 ~]# # 改行(\n)で分割して配列に組み込む
[root@BS-PUB-CENT7-01 ~]# jq --slurp -rR 'gsub("\"";"")|split("\n")' /tmp/sample3.csv
[
"1,1243,A",
"2,24365,B",
"3,201,B",
"4,5465,C",
"5,24,A",
"6,54750,B",
"7,3547,B",
""
]
[root@BS-PUB-CENT7-01 ~]# # さらにカンマ(,)で区切って配列に組み込む
[root@BS-PUB-CENT7-01 ~]# jq -c --slurp -rR 'gsub("\"";"")|split("\n")|map(split(","))' /tmp/sample3.csv
[["1","1243","A"],["2","24365","B"],["3","201","B"],["4","5465","C"],["5","24","A"],["6","54750","B"],["7","3547","B"],[]]
[root@BS-PUB-CENT7-01 ~]# # キー名に組み込んでやる
[root@BS-PUB-CENT7-01 ~]# jq -c --slurp -rR 'gsub("\"";"") |split("\n") | map(split(",")) | map({"id": .[0],"value": .[1],"type": .[2]})' /tmp/sample3.csv
[{"id":"1","value":"1243","type":"A"},{"id":"2","value":"24365","type":"B"},{"id":"3","value":"201","type":"B"},{"id":"4","value":"5465","type":"C"},{"id":"5","value":"24","type":"A"},{"id":"6","value":"54750","type":"B"},{"id":"7","value":"3547","type":"B"},{"id":null,"value":null,"type":null}]
[root@BS-PUB-CENT7-01 ~]# # Nullも入ってきてるので、最後の一行は表示させないようにする
[root@BS-PUB-CENT7-01 ~]# jq -c --slurp -rR 'gsub("\"";"") |split("\n") | map(split(",")) | map({"id": .[0],"value": .[1],"type": .[2]}) | .[:-1]' /tmp/sample3.csv
[{"id":"1","value":"1243","type":"A"},{"id":"2","value":"24365","type":"B"},{"id":"3","value":"201","type":"B"},{"id":"4","value":"5465","type":"C"},{"id":"5","value":"24","type":"A"},{"id":"6","value":"54750","type":"B"},{"id":"7","value":"3547","type":"B"}]ちなみに、頭にヘッダーがついてるCSVの場合はどうすればよいか。
書き方はちょっと汚くなるが、以下のようifで一行目とそれ以外で処理を分けてやる事で対応できる。
[root@BS-PUB-CENT7-01 ~]# cat /tmp/sample3_2.csv
"id","type","value"
1,1243,"A"
2,24365,"B"
3,201,"B"
4,5465,"C"
5,24,"A"
6,54750,"B"
7,3547,"B"
[root@BS-PUB-CENT7-01 ~]# jq -c --slurp -rR 'true as $doHeaders
> |[gsub("\"";"")
> | split("\n")
> | map(split(","))
> | (if $doHeaders then .[0] else [range(0; (.[0] | length)) | tostring] end) as $headers
> | .[if $doHeaders then 1 else 0 end:][]
> | . as $values
> | keys
> | map({($headers[.]): $values[.]})
> ]
> | .[:-1]' /tmp/sample3_2.csv
[[{"id":"1"},{"type":"1243"},{"value":"A"}],[{"id":"2"},{"type":"24365"},{"value":"B"}],[{"id":"3"},{"type":"201"},{"value":"B"}],[{"id":"4"},{"type":"5465"},{"value":"C"}],[{"id":"5"},{"type":"24"},{"value":"A"}],[{"id":"6"},{"type":"54750"},{"value":"B"}],[{"id":"7"},{"type":"3547"},{"value":"B"}]]
[root@BS-PUB-CENT7-01 ~]#
[root@BS-PUB-CENT7-01 ~]# jq -c --slurp -rR 'true as $doHeaders
> |[gsub("\"";"")
> | split("\n")
> | map(split(","))
> | (if $doHeaders then .[0] else [range(0; (.[0] | length)) | tostring] end) as $headers
> | .[if $doHeaders then 1 else 0 end:][]
> | . as $values
> | keys
> | map({($headers[.]): $values[.]})
> ]
> | .[:-1] | .[]' /tmp/sample3_2.csv
[{"id":"1"},{"type":"1243"},{"value":"A"}]
[{"id":"2"},{"type":"24365"},{"value":"B"}]
[{"id":"3"},{"type":"201"},{"value":"B"}]
[{"id":"4"},{"type":"5465"},{"value":"C"}]
[{"id":"5"},{"type":"24"},{"value":"A"}]
[{"id":"6"},{"type":"54750"},{"value":"B"}]
[{"id":"7"},{"type":"3547"},{"value":"B"}]とりあえずこんなトコだろうか。
コレ以外にもいろんな使い方があると思うので、思いついたら随時追記していこう。

