")
前回に引き続き、今回もシェル芸勉強会へ参加してきました。
…風邪ぶり返したので、懇親会は出ず即効で帰ってきましたが。
今回の問題はこちら。
"上田先生の本をちゃんと読んでいればできる"問題をチョイスしたらしい。
(…買ったし読んではいたけど、その時の自分に役たちそうなトコしか読まずに、"あんま使わないっぽいな"と思ったトコは飛ばしてたような気がする。)
今回はいつも持っていってるノート(Ubuntu)ではなくMacからCentOS7につなげて解いていたので、同様に復習もCentOS 7で行う事にする。
なお、問題に使用するデータはgithubに上がっているので、以下のコマンドでローカルに持ってくること。
git clone https://github.com/ryuichiueda/ShellGeiData.gitQ1.
pdfの中身を閲覧し標準出力で出す問題。
pdfの内容を標準出力で出すコマンドとして、pdftotextというコマンドがあるので、それを使うと良いだろう。
(これらを使わずに、stringsなどで取得する方法が無いか調べてみたのだけど、どうもたいていのPDFはzlibのbase64で差分圧縮しているらしい。
今回使われているPDFファイルも、stringsで中身を見ると~/FlateDecode/~とあるので、多分一行は無理ってことで今回は断念した。)
pdftotextは、以下のコマンドでインストール出来る。
yum -y install poppler-utils # RHEL系の場合
apt-get -y install poppler-utils # Debian/Ubuntuの場合
pdftotext -q bba.pdf -[root@test-node Q1]# pdftotext -q bba.pdf -
群馬のシャブばばあ
hoge.txt[2016/02/09 22:30:32]
Q2.
ファイルの中身を、日本語変換して固定長にするという問題。あるべき姿を見ると、固定長は35文字のようなので、それに合わせて分割する必要がある。
元のエンコードはShiftJISで、UTF-8に変換するので、nkfやiconvなどを用いる必要がある。nkfは最近のディストリでは使われていないので、ここではiconvを用いる。
折り返しについては、grepかfoldで実行すると良いようだ。
iconv -f sjis -t utf8 anydata.cp932 | grep -oE .{35}
iconv -f sjis -t utf8 anydata.cp932 | fold -35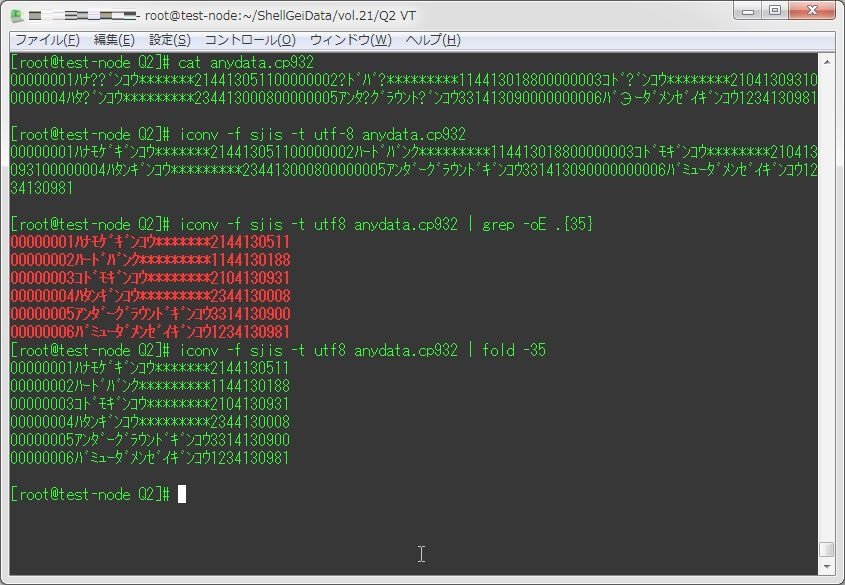
[root@test-node Q2]# cat anydata.cp932
00000001ハナ??゙ンコウ*******214413051100000002?ドバ?*********114413018800000003コド?゙ンコウ********210413093100000004ハタ?゙ンコウ*********234413000800000005アンタ?グラウント?゙ンコウ331413090000000006バЭーダメンゼイギンコウ1234130981
[root@test-node Q2]# iconv -f sjis -t utf-8 anydata.cp932
00000001ハナモゲギンコウ*******214413051100000002ハードバンク*********114413018800000003コドモギンコウ********210413093100000004ハタンギンコウ*********234413000800000005アンダーグラウンドギンコウ331413090000000006バミューダメンゼイギンコウ1234130981
[root@test-node Q2]# iconv -f sjis -t utf8 anydata.cp932 | grep -oE .{35}
00000001ハナモゲギンコウ*******2144130511
00000002ハードバンク*********1144130188
00000003コドモギンコウ********2104130931
00000004ハタンギンコウ*********2344130008
00000005アンダーグラウンドギンコウ3314130900
00000006バミューダメンゼイギンコウ1234130981
[root@test-node Q2]# iconv -f sjis -t utf8 anydata.cp932 | fold -35
00000001ハナモゲギンコウ*******2144130511
00000002ハードバンク*********1144130188
00000003コドモギンコウ********2104130931
00000004ハタンギンコウ*********2344130008
00000005アンダーグラウンドギンコウ3314130900
00000006バミューダメンゼイギンコウ1234130981Q3.
Q3は、2016年の全ての日曜日を出力せよ、と言うもの。
これは結構簡単で、まずechoで2016/01/01~2016/12/31までの日付を出力、それをxargsで1個づつdateコマンドに渡してやって、最後にgrepで日曜日だけ取得すれば良い。
echo '2016/01/01\ +'{0..365}'\ days' | LANG=C xargs -n1 date -d | grep Sunさすがに全日付を記述するのは大変なので、2016/1/1\~2016/1/7で例した結果がこちら。
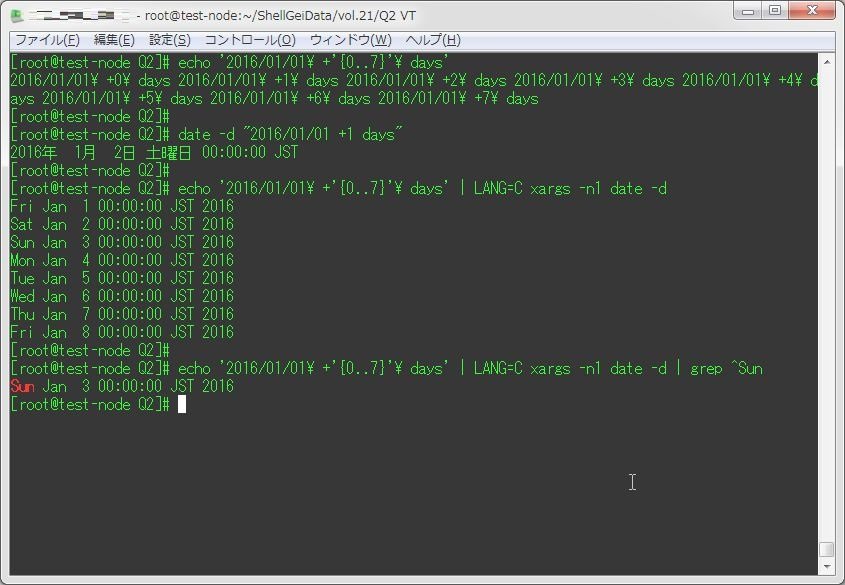
[root@test-node Q2]# echo '2016/01/01\ +'{0..7}'\ days'
2016/01/01\ +0\ days 2016/01/01\ +1\ days 2016/01/01\ +2\ days 2016/01/01\ +3\ days 2016/01/01\ +4\ days 2016/01/01\ +5\ days 2016/01/01\ +6\ days 2016/01/01\ +7\ days
[root@test-node Q2]#
[root@test-node Q2]# date -d "2016/01/01 +1 days"
2016年 1月 2日 土曜日 00:00:00 JST
[root@test-node Q2]#
[root@test-node Q2]# echo '2016/01/01\ +'{0..7}'\ days' | LANG=C xargs -n1 date -d
Fri Jan 1 00:00:00 JST 2016
Sat Jan 2 00:00:00 JST 2016
Sun Jan 3 00:00:00 JST 2016
Mon Jan 4 00:00:00 JST 2016
Tue Jan 5 00:00:00 JST 2016
Wed Jan 6 00:00:00 JST 2016
Thu Jan 7 00:00:00 JST 2016
Fri Jan 8 00:00:00 JST 2016
[root@test-node Q2]#
[root@test-node Q2]# echo '2016/01/01\ +'{0..7}'\ days' | LANG=C xargs -n1 date -d | grep ^Sun
Sun Jan 3 00:00:00 JST 2016Q4.
データベースを模したテキストファイルで、キーに従ってデータをアップデートするイメージの問題。
難しそうだが、sortコマンドだけで解答が可能のようだ。
sort -suk1,1 newdata data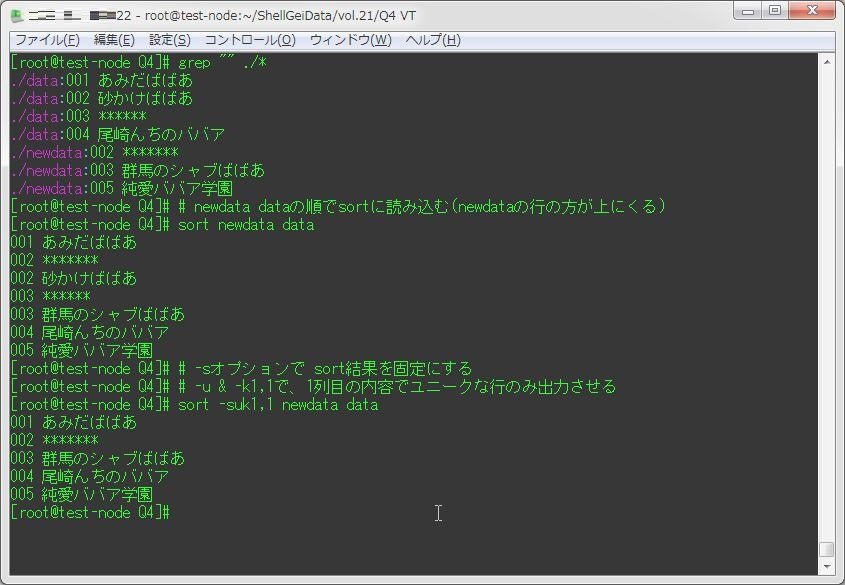
[root@test-node Q4]# grep "" ./*
./data:001 あみだばばあ
./data:002 砂かけばばあ
./data:003 ******
./data:004 尾崎んちのババア
./newdata:002 *******
./newdata:003 群馬のシャブばばあ
./newdata:005 純愛ババア学園
[root@test-node Q4]# # newdata dataの順でsortに読み込む(newdataの行の方が上にくる)
[root@test-node Q4]# sort newdata data
001 あみだばばあ
002 *******
002 砂かけばばあ
003 ******
003 群馬のシャブばばあ
004 尾崎んちのババア
005 純愛ババア学園
[root@test-node Q4]# # -sオプションで sort結果を固定にする
[root@test-node Q4]# # -u & -k1,1で、1列目の内容でユニークな行のみ出力させる
[root@test-node Q4]# sort -suk1,1 newdata data
001 あみだばばあ
002 *******
003 群馬のシャブばばあ
004 尾崎んちのババア
005 純愛ババア学園
Q5.
シェルスクリプトをデバッグせよ、という問題。
一見、何も問題無さそうなんだけど…どうやら、a.bashはBomが、b.bashではチルダが通常使用されるものではないという問題があるようだ。
[root@test-node Q5]# grep "" ./*
./a.bash:#!/bin/bash
./a.bash:
./a.bash:echo Hell
./b.bash:#!/bin/bash
./b.bash:
./b.bash:ls ?/で、デバッグとしては以下のコマンドを実行する。
(b.bashは、teratermだとうまく文字入れられなかったので無理やり置換している)
nkf --overwrite -wLux a.bash # a.bash
sed -i 's/.\//~\//g' b.bash # b.bashQ6.
拡張正規表現を標準正規表現に変換して、bash上で展開しろ、という問題。
たとえば、「a{4}」とあったら、展開して「aaaa」として出力させろ、というもの。
これについては、今のところゴリ押しでいくしかなさそうだ。echoとか、pythonやrubyのprintで展開出来ないか調べてはみたけど無理そう。
以下、解答例。
sed -e 's/[+}]/&\n/g' -e 's/\(.*\)+/\1\1*/' extended | tr '{}()' ' ' | awk 'NF==2{for(i=1;i<=$2;i++){printf $1};print ""}NF==1' | tr -d '\n' | xargs[root@test-node Q6]# sed -e 's/[+}]/&\n/g' -e 's/\(.*\)+/\1\1*/' extended | tr '{}()' ' ' | awk 'NF==2{for(i=1;i<=$2;i++){printf $1};print ""}NF==1' | tr -d '\n' | xargs
a+hhhhhhohohohohohohohohoho[0-9]a+hhhhhhohohohohohohohohoho[0-9]*Q7.
用意されているテキストの、各段落の文字数をカウントするというもの。
模範解答より短く、awkだけで解答することもできるようだ。(どうしてこんなんパッと出てくるんだろう…)
とりあえず、まず模範解答から分解してみる。
cat text | tr -d "\n" | sed 's/ /\n/g' | awk '{print length($1),$1}'[root@test-node Q7]# # 一旦、ファイルの改行を全て削除する
[root@test-node Q7]# cat text | tr -d "\n"
恥の多い生涯を送って来ました。 自分には、人間の生活というものが、見当つかないのです。自分は東北の 田舎に生れましたので、汽車をはじめて見たのは、よほど大きくなってからでした。自分は停車場のブリッジを 、上って、降りて、そうしてそれが線路をまたぎ越えるために造られたものだという事には全然気づかず、ただ それは停車場の構内を外国の遊戯場みたいに、複雑に楽しく、ハイカラにするためにのみ、設備せられてあるも のだとばかり思っていました。しかも、かなり永い間そう思っていたのです。ブリッジの上ったり降りたりは、 自分にはむしろ、ずいぶん垢抜けのした遊戯で、それは鉄道のサーヴィスの中でも、最も気のきいたサーヴィス の一つだと思っていたのですが、のちにそれはただ旅客が線路をまたぎ越えるための頗る実利的な階段に過ぎな いのを発見して、にわかに興が覚めました。 また、自分は子供の頃、絵本で地下鉄道というものを見て、これ もやはり、実利的な必要から案出せられたものではなく、地上の車に乗るよりは、地下の車に乗ったほうが風が わりで面白い遊びだから、とばかり思っていました。
[root@test-node Q7]#
[root@test-node Q7]# # 段落(頭の全角空白)を全て改行に置換する
[root@test-node Q7]# cat text | tr -d "\n" | sed 's/ /\n/g'
恥の多い生涯を送って来ました。
自分には、人間の生活というものが、見当つかないのです。自分は東北の田舎に生れましたので、汽車をはじめ て見たのは、よほど大きくなってからでした。自分は停車場のブリッジを、上って、降りて、そうしてそれが線 路をまたぎ越えるために造られたものだという事には全然気づかず、ただそれは停車場の構内を外国の遊戯場み たいに、複雑に楽しく、ハイカラにするためにのみ、設備せられてあるものだとばかり思っていました。しかも 、かなり永い間そう思っていたのです。ブリッジの上ったり降りたりは、自分にはむしろ、ずいぶん垢抜けのし た遊戯で、それは鉄道のサーヴィスの中でも、最も気のきいたサーヴィスの一つだと思っていたのですが、のち にそれはただ旅客が線路をまたぎ越えるための頗る実利的な階段に過ぎないのを発見して、にわかに興が覚めま した。
また、自分は子供の頃、絵本で地下鉄道というものを見て、これもやはり、実利的な必要から案出せられたもの ではなく、地上の車に乗るよりは、地下の車に乗ったほうが風がわりで面白い遊びだから、とばかり思っていま した。
[root@test-node Q7]#
[root@test-node Q7]# # awkで各行の文字列を取得する
[root@test-node Q7]# cat text | tr -d "\n" | sed 's/ /\n/g' | awk '{print length($1),$1}'
15 恥の多い生涯を送って来ました。
353 自分には、人間の生活というものが、見当つかないのです。自分は東北の田舎に生れましたので、汽車をは じめて見たのは、よほど大きくなってからでした。自分は停車場のブリッジを、上って、降りて、そうしてそれ が線路をまたぎ越えるために造られたものだという事には全然気づかず、ただそれは停車場の構内を外国の遊戯 場みたいに、複雑に楽しく、ハイカラにするためにのみ、設備せられてあるものだとばかり思っていました。し かも、かなり永い間そう思っていたのです。ブリッジの上ったり降りたりは、自分にはむしろ、ずいぶん垢抜け のした遊戯で、それは鉄道のサーヴィスの中でも、最も気のきいたサーヴィスの一つだと思っていたのですが、 のちにそれはただ旅客が線路をまたぎ越えるための頗る実利的な階段に過ぎないのを発見して、にわかに興が覚 めました。
103 また、自分は子供の頃、絵本で地下鉄道というものを見て、これもやはり、実利的な必要から案出せられた ものではなく、地上の車に乗るよりは、地下の車に乗ったほうが風がわりで面白い遊びだから、とばかり思って いました。次に、ebanさんのawkだけで取得するパターン。
(自分の理解のために少し順番変えた)
awk RS=' ' 'gsub(/\n/,"")&&$0=length' text[root@test-node Q7]# awk RS=' ' 'gsub(/\n/,"")&&$0=length' text
15
353
103考え方は、以下であってるんだろか…
- まず、RS=' 'で区切り文字を段落にする
- gsub(/\n/,"")で既存の改行を置換
- ↑と同時(&&)に、$0に1区切りの文字数を代入
$0に値が入っているので、特にprintとかしなくても値が返ってくる。
Q8.
メールのファイルから、画像を抽出するというもの。
uudeviewというコマンドを用いる事で、一発で抽出することが出来る。
RHEL系の場合(CentOS 7で確認)
wget http://www.fpx.de/fp/Software/UUDeview/download/uudeview-0.5.20.tar.gz
tar xzvf uudeview-0.5.20.tar.gz
cd uudeview-0.5.20
./configure
make
make installDebian/Ubuntuの場合
apt-get install uudeviewで、解答は以下。
uudeview -i 1350369599.Vfc03I4682c8M940114.remote[root@test-node Q8]# uudeview -i 1350369599.Vfc03I4682c8M940114.remote
Loaded from 1350369599.Vfc03I4682c8M940114.remote: '2hA|$rE:IU$7$^$9!*' (B2hA): CHINJYU.JPG part 1 Base64
Loaded from 1350369599.Vfc03I4682c8M940114.remote: '2hA|$rE:IU$7$^$9!*' (B2hA): IMG_0965.JPG part 1 Base64
Found 'CHINJYU.JPG' State 16 Base64 Parts 1 OK
Found 'IMG_0965.JPG' State 16 Base64 Parts 1 OK
File successfully written to /root/ShellGeiData/vol.21/Q8/CHINJYU.JPG
File successfully written to /root/ShellGeiData/vol.21/Q8/IMG_0965.JPG
2 files decoded from 1 input file, 0 failedこれで復習は終わり。
…次回こそはもうちょっと上手く解答出来ると良いんだけど(毎回言ってる)。
とりあえず、この世の大体のことはawkが解決してくれるやうである。

