 #1 前半分")
ゴールデンウィーク2日目に、第22回シェル芸勉強会に参加してきたので、その復習。
今回は全体的にawk力が要求されるような問題が多かったようだ。
今回の問題・解答例はこちら。
なんか長くなったので、復習した内容を前半と後半で分けて記述する。
Q1.
各ファイル内の中央値を求める、という問題。
前にこの辺で触れた方法をそのまま持ってくればいけたので、それで対応。
stコマンドが利用できるなら楽なので、入れられる環境なら入れとくとよいだろう。
awkの場合
cat a | sort -n | awk '{v[i++]=$1;}END {x=int((i+1)/2); if(x<(i+1)/2) print (v[x-1]+v[x])/2; else print v[x-1];}'
cat b | sort -n | awk '{v[i++]=$1;}END {x=int((i+1)/2); if(x<(i+1)/2) print (v[x-1]+v[x])/2; else print v[x-1];}'[root@test-node Q1]# cat a | sort -n | awk '{v[i++]=$1;}END {x=int((i+1)/2); if(x<(i+1)/2) print (v[x-1]+v[x])/2; else print v[x-1];}'
3.5
[root@test-node Q1]# cat b | sort -n | awk '{v[i++]=$1;}END {x=int((i+1)/2); if(x<(i+1)/2) print (v[x-1]+v[x])/2; else print v[x-1];}'
3.4stの場合
cat a | st --median
cat b | st --median[root@test-node Q1]# cat a | st --median
3.5
[root@test-node Q1]# cat b | st --median
3.4なお、最初にgrepと組み合わせて一発で各ファイルごとの中央値を出せないか調べていたのだが、うまくsortされなかったので諦めた。
なんで区切り文字もソートキーも、数字順でソートするオプションつけてもうまく行かないのだろうか・・・こんな仕様あったっけ?
[root@test-node Q1]# grep "" ./* | sort -t: -k2n
./b:-5
./b:-4
./a:1
./a:1
./a:2
./a:3
./b:3.4
./a:4
./a:6
./a:6
./a:8
./b:13
./b:4242
[root@test-node Q1]# grep "" ./* | sort -t: -k1,2n
./a:1
./a:1
./a:2
./a:3
./a:4
./a:6
./a:6
./a:8
./b:-4
./b:-5
./b:13
./b:3.4
./b:4242Q2.
2つの単語を、伸ばし棒「ー」でタテヨコで重なるように出力する、という問題。
Q2に移った際、地味にまだQ1で勘違い(一発で各ファイルの中央値を求めるのだと思ってた)して進めてたので、手を付けてなかった。
というわけで、模範解答をまんまのせる。
echo カレーライス 醤油ラーメン |
awk '{print $2;gsub(/./," &\n",$1);print $1}' |
awk 'NR==1{a=$1}NR!=1{print $1==substr(a,4,1)?a:$0}'一応、それぞれを分解するとこんな感じ。
# 最初に文字列を出力させる
echo カレーライス 醤油ラーメン
# 「カレーライス」を縦に出力させる
# ・$2(醤油ラーメン)をprint
# print $2;
# ・$1(カレーライス)をgsubで1文字づつ(/./で何かの文字一文字となる)「 文字\n」と書き換える。
# (この場合、「 カ\n レ\n ー\n ラ\n イ\n ス\n」になる)
# gsub(/./," &\n",$1)
# ・置換した$1をprint
# print $1
echo カレーライス 醤油ラーメン |
awk '{print $2;gsub(/./," &\n",$1);print $1}'
# 「ー」で交差させる
# ・NR==1(1行目)の場合、変数aに1行目の内容を代入(醤油ラーメン)
# NR==1{a=$1}
# ・NR!=1(1行目以外)の場合、変数aの4文字目が$1と同じかを確認し、真の場合変数aを出力する(非の場合$0をまんま出力する)
# NR!=1{print $1==substr(a,4,1)?a:$0}
echo カレーライス 醤油ラーメン |
awk '{print $2;gsub(/./," &\n",$1);print $1}' |
awk 'NR==1{a=$1}NR!=1{print $1==substr(a,4,1)?a:$0}'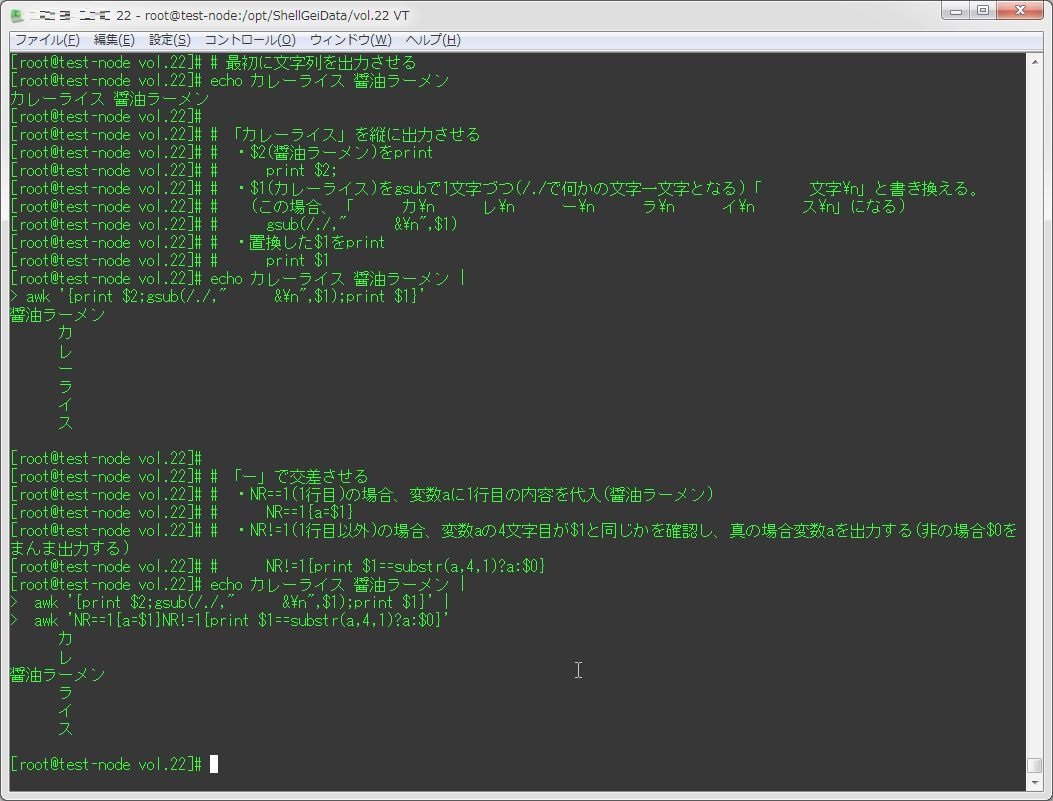
[root@test-node vol.22]# # 最初に文字列を出力させる
[root@test-node vol.22]# echo カレーライス 醤油ラーメン
カレーライス 醤油ラーメン
[root@test-node vol.22]#
[root@test-node vol.22]# # 「カレーライス」を縦に出力させる
[root@test-node vol.22]# # ・$2(醤油ラーメン)をprint
[root@test-node vol.22]# # print $2;
[root@test-node vol.22]# # ・$1(カレーライス)をgsubで1文字づつ(/./で何かの文字一文字となる)「 文字\n」と書き換える。
[root@test-node vol.22]# # (この場合、「 カ\n レ\n ー\n ラ\n イ\n ス\n」になる)
[root@test-node vol.22]# # gsub(/./," &\n",$1)
[root@test-node vol.22]# # ・置換した$1をprint
[root@test-node vol.22]# # print $1
[root@test-node vol.22]# echo カレーライス 醤油ラーメン |
> awk '{print $2;gsub(/./," &\n",$1);print $1}'
醤油ラーメン
カ
レ
ー
ラ
イ
ス
[root@test-node vol.22]#
[root@test-node vol.22]# # 「ー」で交差させる
[root@test-node vol.22]# # ・NR==1(1行目)の場合、変数aに1行目の内容を代入(醤油ラーメン)
[root@test-node vol.22]# # NR==1{a=$1}
[root@test-node vol.22]# # ・NR!=1(1行目以外)の場合、変数aの4文字目が$1と同じかを確認し、真の場合変数aを出力する(非の場合$0を まんま出力する)
[root@test-node vol.22]# # NR!=1{print $1==substr(a,4,1)?a:$0}
[root@test-node vol.22]# echo カレーライス 醤油ラーメン |
> awk '{print $2;gsub(/./," &\n",$1);print $1}' |
> awk 'NR==1{a=$1}NR!=1{print $1==substr(a,4,1)?a:$0}'
カ
レ
醤油ラーメン
ラ
イ
スなお、シェル芸勉強会でよくすごい別解を出されているebanさんの解。
力技
Q2 % echo カレーライス 醤油ラーメン | (read a b;grep -o . $a|sed "3\!s/^/ /;3s/./$b/")#シェル芸— eban (@eban) 2016年4月30日
自分の環境(CentOS 7)だとうまくエスケープ出来なかったので、一部改変して実行。
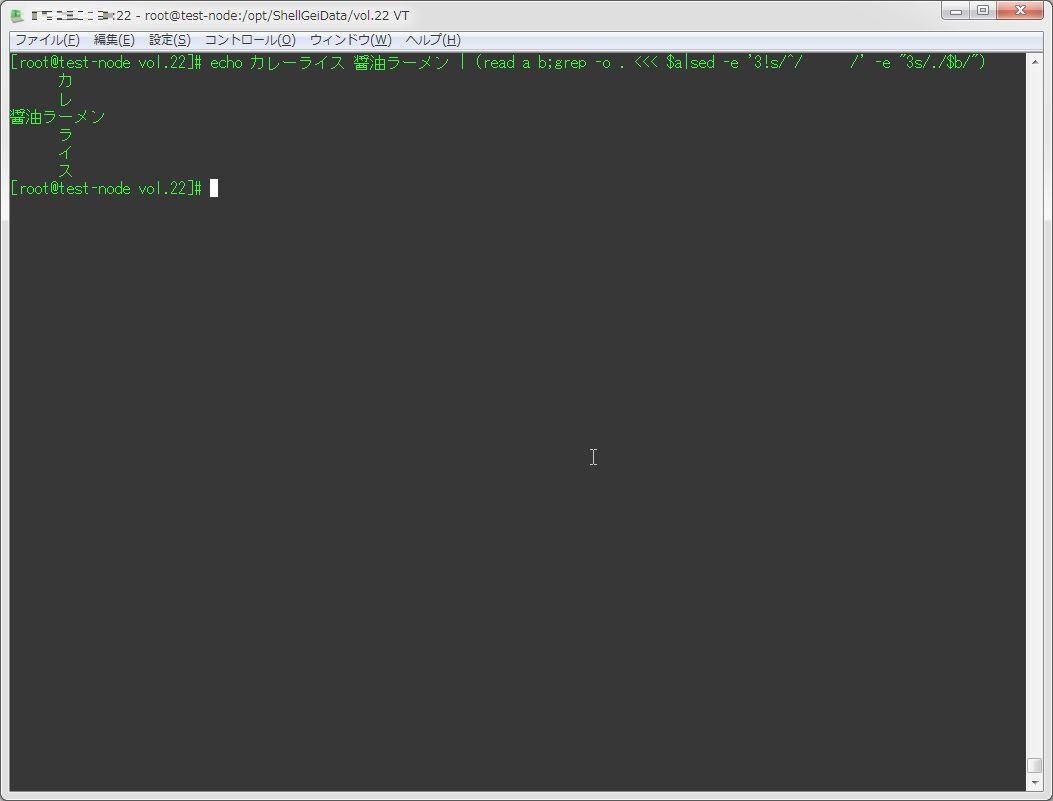
[root@test-node vol.22]# echo カレーライス 醤油ラーメン | (read a b;grep -o . <<< $a|sed -e '3!s/^/ /' -e "3s/./$b/")
カ
レ
醤油ラーメン
ラ
イ
ス分解して考えたのが以下。
# 文字列を出力
echo カレーライス 醤油ラーメン |\
# readで文字列を読込み \
(read a b;\
# grep -o .で、「<<<(ヒアストリング)」の内容を一文字ごとに縦にする \
# grep -o . <<< \
# ヒアストリング内では、$a(カレーライス)はそのまま出力する \
# $a \
# $bは、3行目以外の場合は先頭に空白を代入する \
# '3!s/^/ /' \
# 3行目の場合、文字列を$bに置換する \
# "3s/./$b/" \
grep -o . <<< $a | sed -e '3!s/^/ /' -e "3s/./$b/")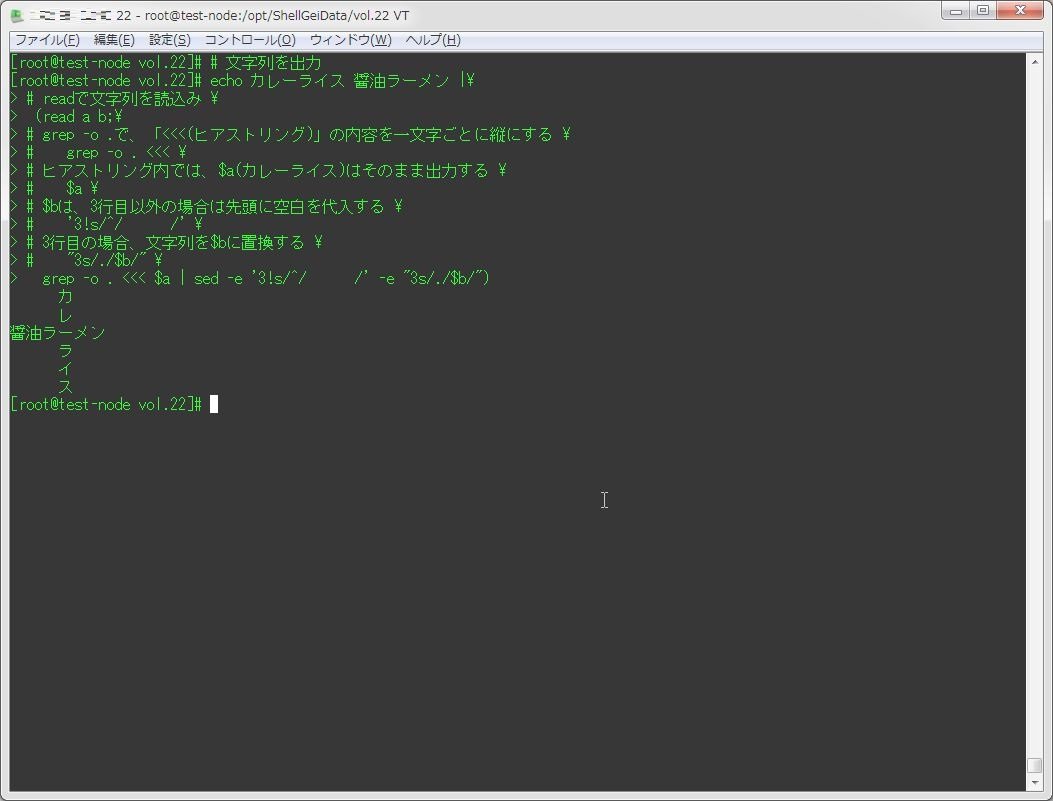
[root@test-node vol.22]# # 文字列を出力
[root@test-node vol.22]# echo カレーライス 醤油ラーメン |\
> # readで文字列を読込み \
> (read a b;\
> # grep -o .で、「<<<(ヒアストリング)」の内容を一文字ごとに縦にする \ > # grep -o . <<< \ > # ヒアストリング内では、$a(カレーライス)はそのまま出力する \
> # $a \
> # $bは、3行目以外の場合は先頭に空白を代入する \
> # '3!s/^/ /' \
> # 3行目の場合、文字列を$bに置換する \
> # "3s/./$b/" \
> grep -o . <<< $a | sed -e '3!s/^/ /' -e "3s/./$b/")
カ
レ
醤油ラーメン
ラ
イ
スQ3.
行が重複しているデータの集計。
これもawkで対応していく問題だ。連想配列を用いる事で対処していく。
まずは前半。分解しての解説も記述しておく。
awk '{a[$1]=a[$1]" "NR}END{for(i in a){print i,a[i]}}' Q3[root@test-node vol.22]# # ・{a[$1]=a[$1]" "NR}
[root@test-node vol.22]# # …$1が同じ場合、NR(行番号)を末尾に追記する
[root@test-node vol.22]# # ・END{for(i in a){print i,a[i]}}
[root@test-node vol.22]# # …END(awk全体の処理の最後)に、各文字列(変数a)ごとの値を出力する
[root@test-node vol.22]# awk '{a[$1]=a[$1]" "NR}END{for(i in a){print i,a[i]}}' Q3
bababa 2 5
aaabbb 1 3 4
bbbbba 6で、これを元の状態に戻す場合。
awk '{for(i=2;i<=NF;i++)print $1,$i}' Q3.ans | sort -k2,2n | awk '{print $1}'[root@test-node vol.22]# # forでNF(列)が2以上の場合、1列目と対象の列を出力していく
[root@test-node vol.22]# awk '{for(i=2;i<=NF;i++)print $1,$i}' Q3.ans
bababa 2
bababa 5
aaabbb 1
aaabbb 3
aaabbb 4
bbbbba 6
[root@test-node vol.22]#
[root@test-node vol.22]# # 2列目の値ごとに数字順で並び替えをする
[root@test-node vol.22]# awk '{for(i=2;i<=NF;i++)print $1,$i}' Q3.ans | sort -k2,2n
aaabbb 1
bababa 2
aaabbb 3
aaabbb 4
bababa 5
bbbbba 6
[root@test-node vol.22]#
[root@test-node vol.22]# # awkで1列目だけを出力する
[root@test-node vol.22]# awk '{for(i=2;i<=NF;i++)print $1,$i}' Q3.ans | sort -k2,2n | awk '{print $1}'
aaabbb
bababa
aaabbb
aaabbb
bababa
bbbbbaQ4.
素数行のみで集計をするという問題(この勉強会、必ず素数出てくるな…)。
factor(素因数分解のコマンド)を利用することで、素数か否かを判定してやると良いようだ。
個人的に出した解としては、joinコマンドを使って結合することで対応した。
join <(cat -n Q4 | sed 's/^[ ]*//g;s/\t/: /g') <(factor {1..100}) | awk 'NF==3{a[$2]++}END{for(i in a)print a[i], i}'[root@test-node vol.22]# cat -n Q4 | sed 's/^[ ]*//g;s/\t/: /g'
1: りんご
2: りんご
3: みかん
4: みかん
5: りんご
6: みかん
7: りんご
8: りんご
[root@test-node vol.22]# factor {1..10}
1:
2: 2
3: 3
4: 2 2
5: 5
6: 2 3
7: 7
8: 2 2 2
9: 3 3
10: 2 5
[root@test-node vol.22]# join <(cat -n Q4 | sed 's/^[ ]*//g;s/\t/: /g') <(factor {1..100})
1: りんご
2: りんご 2
3: みかん 3
4: みかん 2 2
5: りんご 5
6: みかん 2 3
7: りんご 7
8: りんご 2 2 2
[root@test-node vol.22]#
[root@test-node vol.22]# # awkで、列数が3の場合のみ、$2が同じ文字列の数をカウントする
[root@test-node vol.22]# join <(cat -n Q4 | sed 's/^[ ]*//g;s/\t/: /g') <(factor {1..100}) | awk 'NF==3{a[$2]++}END{for(i in a)print a[i], i}'
1 みかん
3 りんごうーん…正直、わかりやすさを考えると「awk 'NF==3{print $2}' | sort | uniq -c」の方が分かりやすかったかも知れない…

