
先日のシェル芸勉強会で、ひらがな以外に対してのgrep処理を調べた際に色々と知見を得られたので、忘れないように残しておく。 一応、grep以外でも文字やASCIIコードでの範囲指定は応用できるはず…。
1. 文字で範囲を指定する
特定の文字を範囲として指定することで、ひらがな・カタカナ・漢字を指定することができる。 以下、範囲の指定。
| 種類 | 範囲指定 |
|---|---|
| ひらがな | [ぁ-ん] |
| カタカナ | [ァ-ン] |
| 漢字 | [亜-熙] |
| 句読点など | [ -】] |
なお、漢字については日本語で利用する漢字を含む範囲をとりあえず囲っているにすぎないので注意。 漢字の部首だったりハングル文字だったり中国語の簡体字・繁体字を除外する場合での記述方法については、こちらを参照すると良いだろう。 句読点については、伸ばし棒なども含まれるので個別に指定したほうが良いかもしれない。
この指定方法であれば、特にオプションを付与せずにgrepで抽出させることができる。
grep [ぁ-ん] 対象ファイル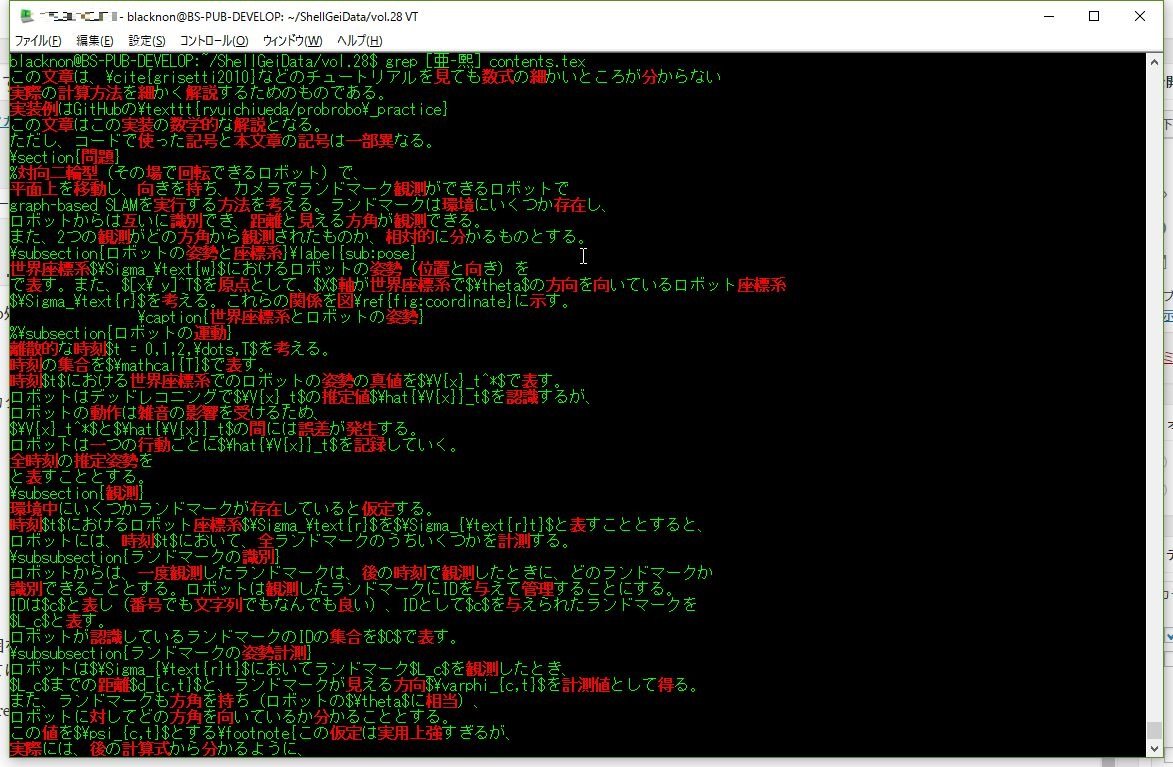
2. ASCIIコードで範囲指定する
上記の指定範囲をASCIIコードで記述した場合。 以下のようになる(Unicodeでの記述。他の形式の場合は随時コード表を参考に書き換え)。
| 種類 | 範囲指定 |
|---|---|
| ひらがな | [\x{3041}-\x{3096}] |
| カタカナ | [\x{30A1}-\x{30FA}] |
| 漢字 | [々〇?\x{3400}-\x{9FFF}\x{F900}-\x{FAFF}\x{20000}-\x{2FFFF}] |
| 句読点など | [\x{3001}-\x{301B}] |
なお、grepでASCIIコードを指定してgrepを行う場合だと-Pオプション(Perlの正規表現での抽出)が必要になる。
grep -P '[\x{3001}-\x{301B}]' 対象ファイル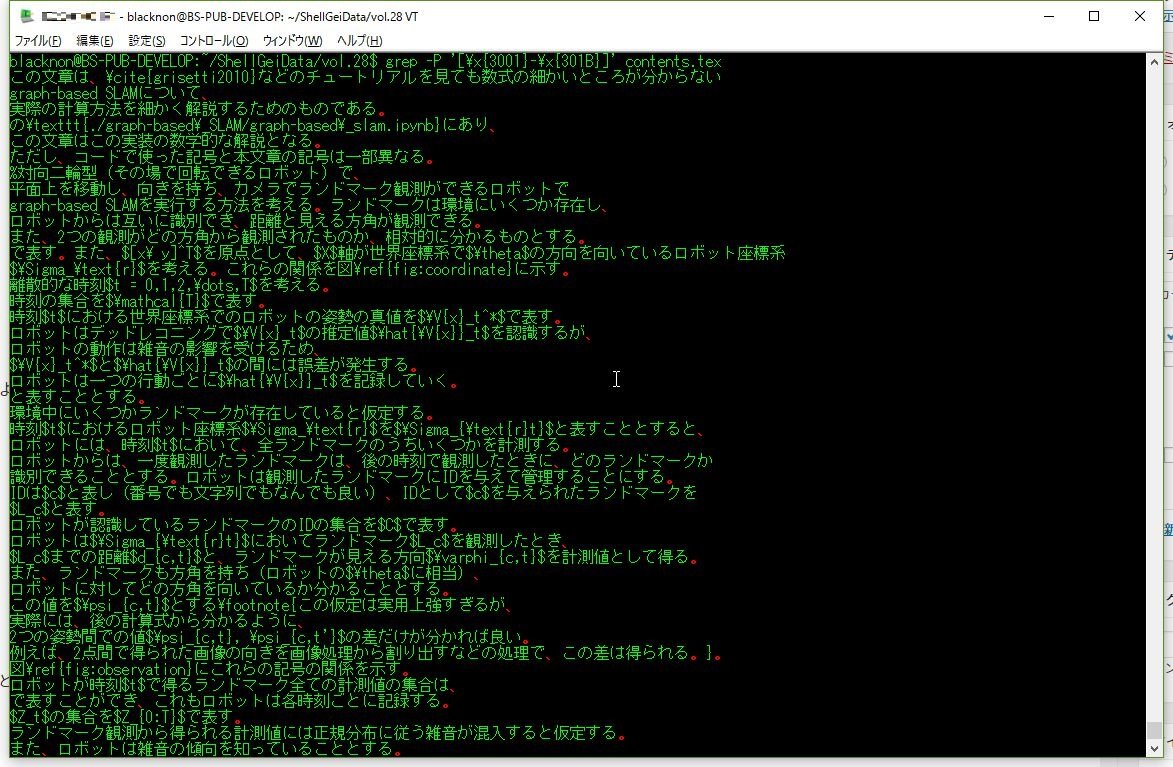
3. PerlのUnicodeプロパティスクリプトを利用する
PerlのUnicodeプロパティスクリプトを利用することで、ひらがな・カタカナ・漢字についてより簡単に指定することができる。 指定可能な一覧はこちらを参考にするといいだろう。
| 種類 | 範囲指定 |
|---|---|
| ひらがな | \p{Hiragana} |
| カタカナ | \p{Katakana} |
| 漢字 | \p{Han} |
記号などについては、\p{Common}でまとめられてしまうので、個別に指定するのが良いだろう。
ちなみに、「\p{~}」で対象の言語のみを、「\P{~}」で対象の言語以外を抽出可能だ。
grep -P '\p{Hiragana}'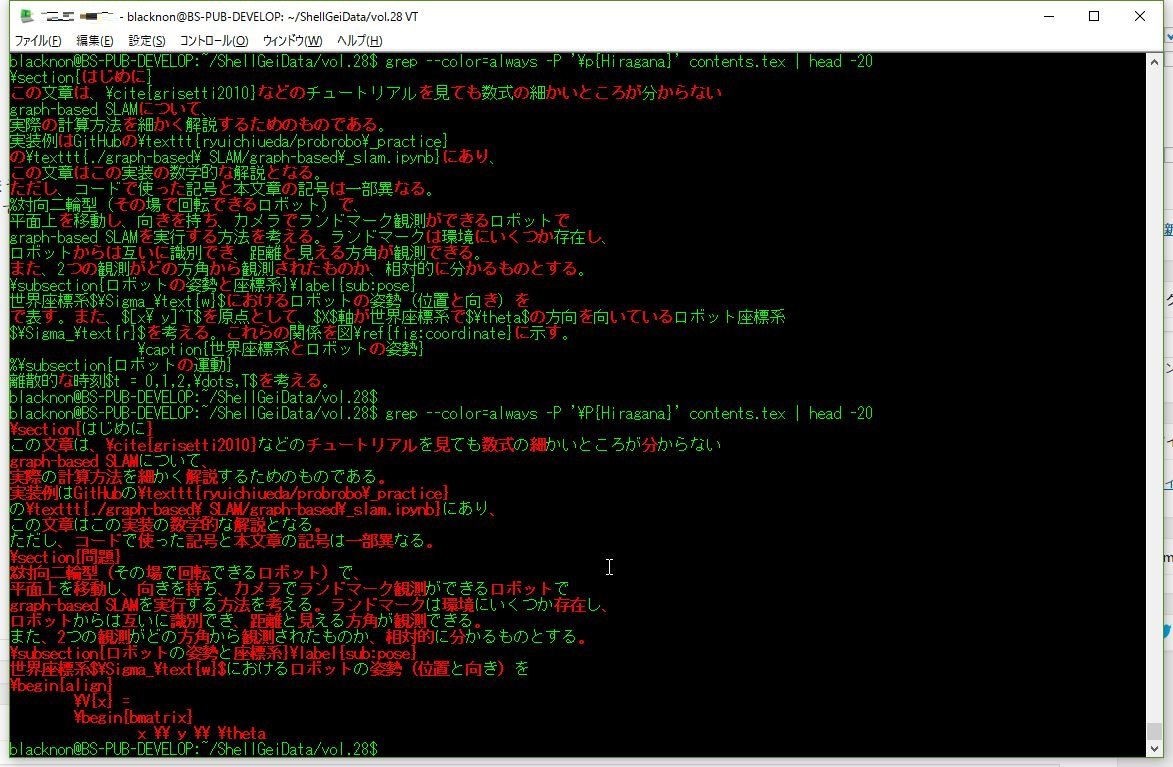
基本、最後のUnicodeプロパティスクリプトを使うのが良さそうだ。

