先日実施された第45回シェル芸勉強会に出席してきたので、その復習。
前回の45回はawkでゴリゴリ解いていくような問題が多かったのだけど、今回はいろんなコマンドを組み合わせて解いていくような問題が多めになっているらしい。
問題および模範解答はこちら。あと、問題を解くに当たって必要になるファイルは以下のコマンドで取得してくる。
git clone https://github.com/ryuichiueda/ShellGeiData
Q1.
csvファイル「data.csv」に、日別のトマト・バナナ・ピーマンの売れた個数が書かれているので、それぞれが記録されている最後の日の日付...
よく作業用のディレクトリとかを一定期間ごとにtar(+gzip)でアーカイブしてあるのだが、たまに過去のデータを調べるためにそのアーカイブしたファイルの中を検索したい事があったりする。
そういった際にいちいちアーカイブを展開して調べるのは面倒なので、なんかいい方法が無いかなと考えていたところ、どうやらGNU tarだと「--to-command」で指定したコマンドに対し、標準入力でtar内のファイルの中身を渡すことができるらしい。
なので、環境変数でtar内のどのファイルなのかも出力させることができる。
ただ標準入力から受け付けてるので、tar内のどのファイルに指定した文字列が含まれて...
あまり仕事とかではないのだけど、たまにコンソール上で全く同じ値を持つ以下のようなテキストから、ユニークな値(今回の場合はB)だけ色を付けたいと思うことがある。
A A A A A A A A A A
A A A A A A A A A A
A A A A A A A A A A
A B A A A A A A A A
A A A A A A A A A A
A A A A A A A A A A
A A A A A A A A A A
A A A A A A A A A A
A A A A A A A A A A
A A A A A A A A A A
一番簡単なのは、grepでユニー...
数年前に、他のターミナルの操作をのぞき見できるttylogというツールについて書いてたのだけど、そのツールの動作を調べてGolangで書き直したという内容の記事を見かけた。
読んでいると、どうやらttylogは以下のステップで他のターミナルの内容をのぞき見しているらしい。
- ttyのログインプロセスのIDを調べる
- pidに対してstraceコマンドを使ってシステムコール(read/write)を見る
- straceの内容を加工して出力する
…あれ?
このくらいの内容なら、straceを使ってgrepや...
Typoしたものが大半なのだけど、指定した文字列とN文字違ったり、1文字ずれている(「あいうえお」→「いあうえお」みたいな)文字列をヒットさせたいということがごくごくたま~にあって、それをgrepでときどきやっている。
個人のマシンではfunctionを作ってあるのだけど、たま~にリモートマシンで使うとき(+ローカルのrcファイルを読み込ませてない時)なんかにはその場でコマンドを組み合わせたりしているので、備忘で残しておく。
1文字違う文字列をgrepする
指定した文字列から1文字違う文字列をgrepする場合、以下のようにする。
以前、『メディア芸術データベース』のAPIからジャンプで打ち切られたマンガの一覧を取得しようと試みた事があったのだが、今回はより正確性を高めるためにWikipediaのジャンプの連載一覧から打ち切りマンガの一覧を作成してみる。
正直、スクレイピングならPythonでpandasとか使ったほうが楽だったりするのだけど、最初にシェル芸でやると決めたので初志貫徹やってみた。
ちょっと汚いけど、以下のようにコマンドを実行することで一年以内で連載が終わってしまった(短期集中や遺跡、続編を除く)作品の一覧を作成できる(こっちにも念の為残してある)。
(多分もうちょっときれいにできるだろうけど、そん...
先日実施された、第36回シェル芸勉強会に参加してきたので、その復習。なんか、ブログの記事自体をすごく久しぶりに書いた気がする(個人的にRustで簡単なツール作ってるのだけど、難しすぎてそっちにリソース全振り中…。ある程度動くようにはなったけどいつ終わるのやら…簡単なはずだったのに…)。
大体いつもむずかしめの問題が多いのだけど、今回も難しかった。
問題及び模範解答はこちら。最初に、問題等に使用するファイルをgitからcloneしておくといい。
Q1.
「welcome.txt」というファイルに隠されたメッセージを読み取れ、という内容。
単純にcatしただけだとアンダーバーし...
ちょっとシェル芸botで遊んでいた際、ふと畳語(ワンワンとかドキドキとかムラムラ、ビンビン、ヌレヌレなど、反復する言葉)を抽出したり、置換するにはどうすればいいかなと思ったので、やってみることにした。
なお、grepやsedについては使用するのはGNU拡張されたものを用いるので、Mac OS Xに入っているgrepやsedでは同じことができないかもしれないので注意。
1.抽出する場合
GNU grepにはPerl正規表現を利用できるオプションがあるので、以下のように記述することで畳語を抽出できる。
(Perlの正規表現を使うことでunicode propertiesが利用できるよう...
先日実施された、第35回シェル芸勉強会に参加してきたのでその復習(第34回は腰をやって参加してないので、1個空いちゃったなー…)。
今回は、前半はそこまで厳しく無かったのだが、後半が結構難しかったので中々疲れた。
問題及び模範解答はこちら。最初に、問題等に使用するファイルをgitからcloneしておくといい。
git clone https://github.com/ryuichiueda/ShellGeiData.git
Q1.
ちょっと前に話題になっていた、curlでアクセスするとアスキーアートのParty Parrotがターミナル上で動き出すサービスをの出力をファイル...
諸事情あってascii以外の文字列をファイルから排除する必要があったので、備忘として正規表現を残しておく。
以下のように、Perlの正規表現を使ってやることでascii以外の文字を含む行を排除できる。
grep -v -P '[^\x00-\x7F]' FILE
ふとした思いつきで、アラビア数字から漢数字への変換をコンソール上でできないかなーと思ったのでやってみることにした。
以下のように、まず一度sedで全部漢数字に切り替えて、その後は各桁に応じて漢字の置き換えをしていくことで対応できるようだ。
echo 123456789 | sed 'y/0123456789/〇一二三四五六七八九/' | grep -o . | tac | paste - <(echo {十,百,千,万,十,百,千,億} | fmt -1 | cat <(echo) -) | grep -vE ^$'\t' | tac | sed -zr 's/(\t|\n)//g'| perl -lpe 's/一(?!($|万|億))//g;s/〇(?!$)//g'
Twitterをボケーッと見てたところ、そんな感じの処理についてしたいというツイート見かけたので、備忘で残しておく。
urlの箇所をgrepするだけであれば、以下のように正規表現を記述してやればいい。
※マルチバイト非対応。日本語を含む場合はパーセントエンコーディングである必要あり。
grep -zoP -- 'http(s?)://[0-9a-zA-Z?=#+_&:/.%]+'
blacknon@BS-PUB-DEVELOP:~$ cat test_url1.list
yyy="https://example.co.jp/test...
コンソール上で、同じ文字の繰り返し(ゾロ目とか)を抽出、置換したいことがあったので、備忘で残しておく事にする。
抽出する場合は、以下のようにgrepで正規表現を書いてやる。
Nのトコはゾロ目の数-1の数字を入れてやる。
grep -oE '(.)\1{N}'
[root@BS-PUB-CENT7-01 test_dir]# seq -w 0 999 | grep -E '(.)\1{2}'
000
111
222
333
444
555
666
777
888
999
置換する場合も同様で、sedで以下のように記述してやればいい。
ふと、先日のシェル芸勉強会のQ7みたいな「連続したn文字の組み合わせ」を羅列させたいなと思ったので、ちょっと調べてみた。
とりあえず、以下のように記述することでn文字の組合せを出力できる。
ちなみにsedのブレース展開で件数を処理しているため、開始が2からになっている。
sed -e'p;1s/^.//g;'#{2..n}|(X=$(cat);echo "$X"|grep -Eo .{$(wc -l<<<"$X")})|sort
第30回シェル芸勉強会に行ってきたので、その復習。
問題、解説はこちら。
今回は、前半の問題は対象の知識があるかどうかに重きを置いていた様子。
後半はいつものような内容の問題だったので、個人的には後半のほうが取っ付きやすい印象だった。
Q1.
特定ディレクトリ配下から、「main.md」ファイルのみを対象に2行目の「Keywords:」行を抽出するという問題。
最初、2行目のみを抽出するためにawkを利用する方法を取っていた。
find ./posts/ -name main.md | xargs grep -n Keywords | awk -F: '$2==2{OFS=...
ちょっと前にsedとブレース展開を使ってLeet変換した文字列の一覧を羅列するという処理についてやってたのだが、ふと特定の文字列がLeet変換されている文字列をgrepする場合どうすれば良いのかなと思い調べてみたので、備忘として残しておく。
grepには-fオプション(指定されたファイルの中にある文字列からgrepする)があるので、特に難しいこともなくプロセス置換で実現できる。Leetの組合せは状況に応じて足していけばいい。
grep -i -f <(eval echo $(echo 文字列 | sed -e 's/a/{a,@}/g' -e 's/s/{s,\\\$}/g' -e 's/o/{o,0}/g') | tr ' ' '\n') /tmp/test.txt
ログの監視やなんやらで、tail -Fなどと組み合わせて使用する機会の多いsedやawk、grepだが、デフォルトの動作ではバッファリングされてしまう。
これをバッファしないように実行する場合、以下のようにコマンドを実行する。
sedの場合
GNU拡張されているsedの場合、-uオプションというオプションがあるので、それを用いる。
sed -u '~'
sed --unbuffered '~'
注意したいのが、Mac OS XのsedコマンドなどGNU拡張でないsedの場合、-uオプションが無い。
この場合は、後述するstdbufを用いるか、(どっちにしろcoreuti...
ちょっとした作業で、日付やタイムスタンプを取得する必要があったので、一応念の為残しておく。

ふと、特定のファイルに対して、指定したキーワードが◯行目に何個含まれているのかをターミナル上で取得できないかなと思ったので試してみた。
例えば、以下のようなファイルで、各行にあるABCの数をそれぞれ求める場合。
blacknon@BS-PUB-DEVELOP:~$ cat test3.txt
ABC123DEF431ABC
112rtr333ABC
ABC3435dfs343ABCABC
ABC23435ABC
ABC334535
g4wsdgr
ABCt3wt3
こういった場合は、grepのn オプション、o オプションを利用することで、比較的簡単に求める事が可能だ。
...
grepでメールアドレスを抽出する場合、正規表現を書いて抽出するのが楽になる。
とりあえず、以下のように記述してやることで、メールアドレスと思われるものを抽出することができる。
grep -E "[-_a-zA-Z0-9\.+]+@[-a-zA-Z0-9\.]+"

先日のシェル芸勉強会で、ひらがな以外に対してのgrep処理を調べた際に色々と知見を得られたので、忘れないように残しておく。
一応、grep以外でも文字やASCIIコードでの範囲指定は応用できるはず…。
1. 文字で範囲を指定する
特定の文字を範囲として指定することで、ひらがな・カタカナ・漢字を指定することができる。
以下、範囲の指定。
| 種類 |
範囲指定 |
|---|
| ひらがな |
[ぁ-ん] |
| カタカナ |
[ァ-ン] |
| 漢字 |
[亜-熙] |
| 句読点など |
[ -】] |
なお、漢字については日本語で利用する漢字を含む範囲をとりあえず囲っているにすぎないので注意。
漢字の部首だっ...
第28回シェル芸勉強会に行ってきたので、その復習。
今回はLaTeXのファイルに対して、特定箇所の抽出やらを行っていく形式。
正直、かなり難しかった…。
前回もそうだったけど、ほとんどついていけなかった。
よくわからなかったトコについては、回答できた人の内容を分解して理解を進めることにする。
問題および模範解答はこちら。
問題で使用するファイルは、(1ファイルしかないけど)以下のコマンドでダウンロードすると良いだろう。
git clone https://github.com/ryuichiueda/ShellGeiData.git
Q1.
まずはQ1。これは簡単で、そ...
ふと思い立ったので、ターミナル上でファイルから頻出しているキーワード(スペース区切り)・文字を取得させてみることにする。
特に難しいことはなく、以下のように簡単に行える。
1. スペース区切りの頻出キーワードを抽出する
スペース区切りの頻出キーワードを抽出する場合は、以下のようにする。
コマンド | sed 's/ /\n/g;s/\t/\n/g' | grep -v ^$ | sort | uniq -c | sort -nr | head -20
例として、lsのmanの内容で抽出した結果が以下。
blacknon@BS-PUB-UBUNTU-01:~$ man ls...
ちょっと前に、シェル芸で文章から縦読みをgrepするということをやってたので、今回は斜め読みをしてみる。
基本は縦読みと対して変わらず、その応用になる。以下、実行した際のコマンド。

ふと、文章の中に縦読みで特定の文字列が仕込まれていないかどうか、シェル芸で確認できないかなと思ったのでやってみた。
至極当たり前の話として、grepは行に対して処理を行うので縦書きのものには利用できない。
で、じゃあどうすればいいのか。
縦書きに対して処理できないなら、横書きに変換してしまえばいい。
縦書きから横書きに変換するのは、結構前に表に対して同様の処理を行っていたので、それを応用してやれば良い。
ちょっと長くなるけど、awkでやった際のコマンドが以下。
先日、2017年02月24日よりプレミアムフライデーなるモノが始まった。
これは、毎月の最終金曜日は15時退社にして余暇を作ることで個人消費を増やし、景気促進を促すという経産省主導の消費喚起のプログラムなのだが、あいにくと導入している企業は0.1%前後とかで、今の時点だとプレミアムな企業にしか適用されてないようだ(プレミアムな企業だったら給料も高いので、消費喚起という意味ではまぁ間違ってない…のか?景気対策としての効果は疑問だけど、まぁ結果を見てからかなぁ…)。
で、じゃあ今年のプレミアムフライデーは何日なのかをコンソール上で出力させてってみよう。
日付関係の処理を行うといえばdateコ...
を調べる")
前に、「〇んこ」みたいな伏字の候補をシェル芸で見つけたりしてたのだが、ふと「類義語」ってコンソール上で得ることができないのかな…?と思い調べてみた。
調べてたら「日本語WordNet」なる日本語辞書のプロジェクトがあるらしい。
基本は辞書ファイル(sqlite3)をダウンロードして使うようなのだが、こちらにWebから検索できるものがあった。
ということはスクレイピングをすればいけるだろうということで、実際にやってみることにした。
で、その結果。
grepだけで抽出できるかと思ったけど、ちょっとうまくいかなかった。
curl -s --data "lemma=ちんこ&...
ログなどで日付や時刻、その範囲を抽出する際だとgrepやawkなどを使って頑張ることが多いのだが、なんか他いいコマンドないかなと調べていたところ、Perlで記述された『dategrep』というコマンドがあるようだ。
名前そのままに、日付でファイルやログをgrepできるツールのようだ。
以下のようにコマンドを実行してインストールする。
(cpanからもインストールできるが、うまく動作しなかった)
git clone https://github.com/mdom/dategrep
cd dategrep/
sudo sh -c 'perl Makefile.PL && make...
最近ちょこちょこPythonを触る機会が多くなってきたのだが、処理の中でgrepやawkのように行の抽出をさせたいことがある。
Subprocessでgrepとかawkを呼び出すのはかっこ悪いし、Python内で処理を完結させたいというのもあったので少し調べてみた。
1.指定した文字列を含む行を抽出
1-1.基本的な抽出方法
Pythonでgrepのような処理を行うには、find('文字列')を用いてその文字列を含む数を指定することで抽出が可能だ。
以下、記述例。
# -*- coding: utf-8 -*
import sys
ld = open(sys.argv[1])...

ネットワーク回りのログや調査をしていると、IPアドレスやMACアドレスだけをgrepで抽出したいことがある。
その場合は、それぞれ以下のようにgrepを実行するとよい。
IPアドレス
grep -E '([1-2]?[0-9]{0,2}\.){3,3}[1-2]?[0-9]{0,2}'
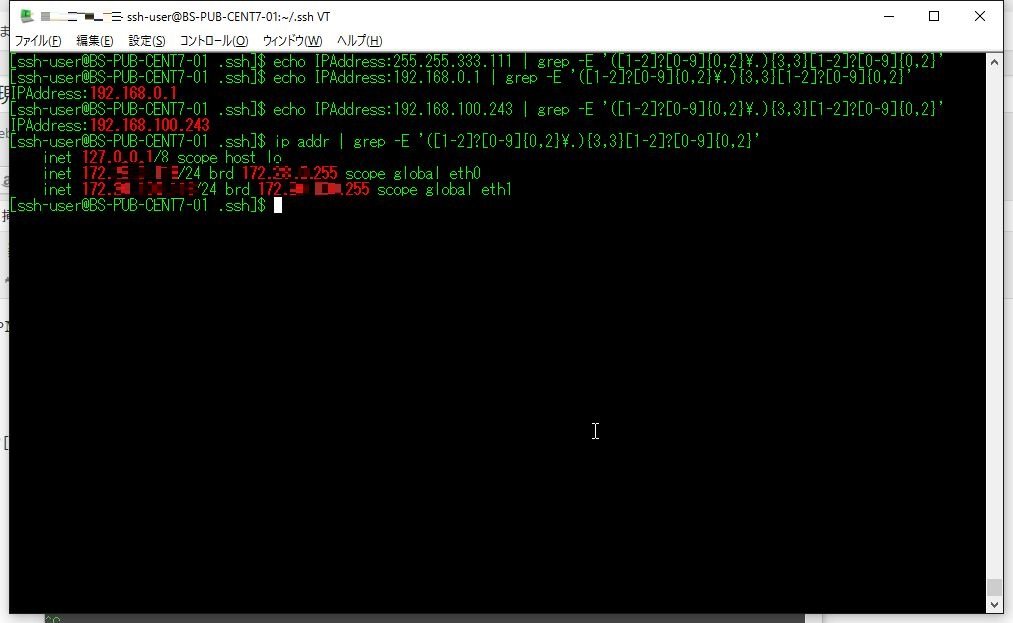
[ssh-user@BS-PUB-CENT7-01 .ssh]$ echo IPAddress:255.255.333.111 | grep -E '([1-2]?[0-9]{0,2}\.){3,3}[1-2]?[0-9]{0,2}'
[ssh-user@BS-PUB-CENT7-01 .ss...
