久しぶりにPythonのバージョンを上げてみたところ、なぜかPython3.8のときには動作していた以下のようなプログラムで、『can't register atexit after shutdown』というエラーが出るようになった。
なんだろうなと思ったのだが、どうもthreadingでちゃんとjoinを待たないとエラーになるようになったらしい。 (ちゃんとjoinしてたつもりだったけど、どうも別の処理と混同していた...
久しぶりにPythonのバージョンを上げてみたところ、なぜかPython3.8のときには動作していた以下のようなプログラムで、『can't register atexit after shutdown』というエラーが出るようになった。
なんだろうなと思ったのだが、どうもthreadingでちゃんとjoinを待たないとエラーになるようになったらしい。 (ちゃんとjoinしてたつもりだったけど、どうも別の処理と混同していた...
pythonで簡単なCUIのツールを作っていたとき、pipでインストール時にbash/zshの補完ファイルも一緒にインストールさせたいというのがあったので、やり方について調べてみた。 で、結論としては以下のようなsetup.pyを作成すれば良さそうだということがわかった。
ちょっとしたツールをPythonで作ったので、pipインストールできるように以下のようにsetup.pyを書いてたのだけど、どうもinstall_requiresが処理されないということがあった。
setup.pyimport os import platform import setuptools from hoge import __version__ if __name__ == "__main__": setuptools.setup( name='hoge', version=__version__, ins...
Linuxでなにかしら処理を動かしていると、処理が終了した際にローカルのユーザにメールを送ってくることが多い(デフォルトでは/var/spool/mail/にファイルとして吐かれてる場合が多い(mbox形式))。
ちゃんとしたサーバだったら監視ツールとか入れたり、別途Slackにポストさせたり、ちゃんとメーリングリスト宛にメールを転送させるように設定したりしているけど、適当にCUIでキックした処理の終了連絡とか、cronで定期実行してる処理だとそこまでしてなかったりする。
で、そもそも最近はメールもあまり見ないし、Slackにはメールを受け付けてチャンネルにPOSTしてく...
ちょっと前にPython3でコードを書いていた際、複数の変数の値すべてがNoneだった場合にTrueとする処理にしたいということがあったので、備忘で残しておく。 やり方としては簡単で、一度すべての値を配列に入れてやって、それをlist.count(None)で数えてやった値と配列の要素数を比較してやればいいだけだ。
Elasticsearch 5.3に対してPythonからアクセスする際、Indexはワイルドカード指定できるのだけど、Typeについてはワイルドカードでの指定ができない。 一応、カンマ区切りで複数の指定は可能なのだけど、あまりにTypeの数が多くなるとhttpのエラーでクエリを実行できなくなってしまう。で、なんかいい方法ないのかなと調べていたのだけど、どうやらクエリ側にprefixとして_typeを定義してやることで、ワイルドカードでの指定と同じようなことができるようだ。
ElasticsearchのIndex/Typeを分割する必要があり、クエリを投げる前にIndex/Typeの一覧を取得する必要が出た。で、どうやって取得すればいいかというのだけ念の為残しておく。 残念ながらそのものズバリな関数はライブラリに無いっぽいので、Mapping情報を取得して、そこから抽出する方法になってしまう(connはElasticsearchとの接続用)。
調べた際に、そのものズバリで引っかからなかったので念の為残しておく。
以下のように、bulk処理をtryで実行し、exceptでhelpers.BulkIndexError.errorsを指定することで、エラーリストを取得できるようだ。
Pythonでmultiprocessingを行う際、各プロセスの返り値を取得したいということがあったので備忘として残しておく。
色々と調べてみたところ、以下のように multiprocessing.Pipe を使って返り値を配列として取得し、それを後ほど分解するのがよさそうだ。
import multiprocessing
def worker(string, send_rev):
result = str(string) + '_result'
send_rev.send(result)
def main():
job_list = []
pip...ElasticsearchでAggregationsを使って集計処理を行っていたところ、どうも件数が少なかった。 で調べてみたところ、どうやら抽出結果と同じくこちらもデフォルトでは10件までしか取得できないらしい。
で、集計結果を10件以上取得するにはどうすれば良いのかなと調べてみたところ、どうやらクエリ内でサイズを指定して、そこから取得する必要があるようだ。上限は10,000件らしい。
s_base_query = {
'query':{'bool':{'must':[],'should':[]}},
'size': 0,
'a...PythonからElasticsearchへや大量にクエリ(indexだけではなくcreateやupdate、deleteも)を投げる処理を行う必要があったので、Bulkでまとめて処理をさせることになった。 Bulk処理をさせる場合、helpersがよく使用されているので今回はそれを利用する。以下のように記述することで、createやupdate、deleteについてbulk処理を行わせる事ができる。以下の例では、dataに入っている各データをcreateでbulk処理させている(Elasticsearchへの接続処理等は省略)。
es_index = 'INDEX'
es_doc = '...システムの監視などで、WEBサービスの死活監視(外形監視)の際にSSL証明書なども一緒に監視する事はあるのだけど、ついででドメインの更新期日なども一緒に確認したいことがある。 だが、ドメイン情報を取得する際に使用するwhoisはドメインの種類によってフォーマットが全く違う(項目名すら違う)ため、汎用的に情報を取得することができない。 ドメイン期限とか、.jpだと項目すら無い。 whoisの次世代プロトコル「RDAP」というものも出てきてるようだけど、2017年11月時点ではまだ実用フェーズまではきてないようなので、この時点では利用できない。
で、なんかいい方法ないかなーと調べてみたとこ...
コンソール上で特定の文字列をワンライナーで指定回数リピートさせたい(例えば、0を10回リピート等)ということがあったので、備忘で残しておく。 いくつか方法があるようなので、それぞれ分けて残しておく。
真っ先に利用する方法として思いつくのはブレース展開だと思う。 ただ、以下のように普通にechoにくっつけて利用すると展開時にはスペース区切りになってしまう。
echo 0{,,,,,}blacknon@BS-PUB-UBUNTU-01:~$ echo 0{,,,,,}
0 0 0 0 0 0一応、前にブレース展開の出力区切り文字を変更するの...
PythonのスクリプトでDBから日本語を含む文字列を扱った際、『UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3』といったエラーが出た。 これは、Pythonでは明示的に指定しないとデフォルトエンコーディングがasciiになっているため、UTF-8がそのまま利用できないのが理由のようだ。
blacknon@BS-PUB-UBUNTU-01:~$ python
Python 2.7.12 (default, Nov 19 2016, 06:48:10)
[GCC 5.4.0 20160609] on linux2
Type "...前回、torをUbuntu/CentOSへインストールし利用できるようにしたので、今回はPythonからtor経由でのアクセスを行うようにする。 色々なやり方はあるようなので、2つほど試してみる。
requestsのforkでsocksを使うことができるパッケージがあるので、これで対応するのが楽そうだ。 事前にpipでインストールをしておく。
sudo pip install -U requests[socks]後は、以下のように使用してtor経由でアクセスをすると良い。
#!/usr/bin/python
# -*- coding:...以前sedで行った内容について、Pythonで書き換える必要があったので一応備忘で残しとく。 特に難しい処理をするわけでもなく、文字列を読み込んで1文字づつ大文字・小文字・数字に合わせて処理をしてやればいいだけだ。 今回は、各文字列についてgrepの正規表現に書き換えてやるようにする。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
upper = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W'...Pythonで、配列の比較を行って片方にしか無い要素を取得したいという場合、setにすることでそういった比較が行えるようだったので備忘で残しておく。 以下のように配列を作成して、setにして比較をしてやればいい。 なお、set生成時に重複した値は削除される。
a = [1,2,3,5,8,11,1,2]
b = [1,3,5,7,9]
set_a = set(a)
set_b = set(b)
# 重複した値は削除されている
print(set_a)
# 配列「a」にしかない要素を取得
print(set_a - set_b)
# 配列「b」にしかない要素を取得
print(set...先日、sedとブレース展開を用いて文字列の大文字・小文字・Leet変換全ての組み合わせを取得するという処理についてやったが、今回は同じようなことをPythonでやるにはどうすればいいか調べてみた。 Pythonでは、itertoolsというモジュールを使うことで、この組み合わせを簡単に生成できるようだ。
以下のように、組み合わせとなる文字列をリストに入れておき、それを利用することでリストが取得できる。
leetlist.py#!/usr/bin/python # -*- coding: utf-8 -*- import sys from itertools impor...
bashで、パイプで渡した値をエスケープした状態で出力させる必要があったので、備忘で残しておく。 sedやawk、printfなどでできる。
sed -e 's/[][^$.*?+!\\()&|'\''"]/\\&/g'blacknon@BS-PUB-UBUNTU-01:~$ cat test.list
'aaaa&aa#a
b\bb"
sx$sss!
blacknon@BS-PUB-UBUNTU-01:~$ cat test.list | sed -e 's/[][^$.*?+!\\()&|'\''"]/\\&/g'
\'aaaa\&aa#a
b\\bb\"...ちょっとしたスクリプトをPythonで作成しようとしてて、バージョン番号の比較をさせる必要があったので備忘として残しておく。 Pythonでバージョン番号の比較を行う場合は、以下の2つの方法があるようだ。
『distutils.version』を利用することで、バージョン番号の比較が行えるようだ。 以下のようにインポートして関数を利用、比較してやれば良いようだ。
比較用の関数は2つ用意されており、「StrictVersion」と「LooseVersion」が利用できる。 アルファベットを含むような、数字だけではないバージョン番号...
ふと、コンソール上で特定の単語の文字組み合わせを取得するにはどうすればよいのかなと思ったので、ちょっと調べてみた。 ブレース展開を増殖させる方法でどうにか…と思ったけど、無駄に長くなったうえに、文字すべての組み合わせになってしまう。 これをどうにかする方法は見つけることができなかった…。
TEST=$(echo test) && eval echo $(eval echo $(echo $TEST | xargs -I@ sh -c 'echo \"{$(echo @ | sed "s/./&,/g;s/.$//g")}\"{$(echo @ | sed "s/./,/g;s/.$//g...Linuxでどこぞから持ってきたPython(2.x系)のスクリプトをキックした際、「UnicodeDecodeError: 'ascii' codec can't decode byte 0xc2 in position 0: ordinal not in range(128)」というエラーが出てしまうことがある。
これは現在スクリプトをキックしているPythonのデフォルトが'ascii'になっていることが原因のようなので、これを'utf-8'に変更してやることで暫定対応ができる(ほんとはソース直せって話なんだろうが)。
blacknon@BS-PUB-UBUNTU-01:~$ p...
前に、AWSでの各サービス利用料金通知Botを作ってたので、Azureについても作成してみた。 ソースはとりあえずこちらに配置している。
…正直、AWSに比べてえらい作りにくかった。 AWSの場合だと一発でJSONでデータとれるのだが、Azureは各サービスの利用データとその利用データごとのレート金額で分かれているので、データを取ってきたあとにマージしてやる必要があった。 あと、どうも日本リージョンのデータを取得する際にドルで取ってこれないようで、日本円で計算する必要があった。 為替の変動とかに影響受けそうなんだけど、どうなんだろう…?
この辺の情報はソースに直書きになっている...
最近ちょこちょこPythonを触る機会が多くなってきたのだが、処理の中でgrepやawkのように行の抽出をさせたいことがある。 Subprocessでgrepとかawkを呼び出すのはかっこ悪いし、Python内で処理を完結させたいというのもあったので少し調べてみた。
Pythonでgrepのような処理を行うには、find('文字列')を用いてその文字列を含む数を指定することで抽出が可能だ。 以下、記述例。
# -*- coding: utf-8 -*
import sys
ld = open(sys.argv[1])...PythonのSubprocessでBashのパイプを利用したコマンドを実行したい場合、いくつかの方法があるようだ。
subprocessでは、コマンド実行時にsubprocess.PIPEを使ってstdoutやstderrを変数に代入することができる。 さらにstdinを変数から取得させることができるので、これを利用して出力結果を渡してやればよい。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import subprocess,shlex
command1 = 'ls /'
comm...PythonのSubprocessでOSのコマンドを実行した際、デフォルトの動作だとその実行結果(stdout/stderrともに)はコンソール上に出力してしまう(スクリプト化してても同様)。
[root@BS-PUB-CENT7-01 ~]# # そのままSubprocessを実行すると、結果が出力されてしまう
[root@BS-PUB-CENT7-01 ~]# cat /tmp/test.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import subprocess,shlex
command = 'ls /'
subproces...pipなどでのインストール中に『致命的エラー: Python.h: そのようなファイルやディレクトリはありません』と言われる場合は、python-devel(python-dev)がないことが原因だ。
以下のコマンドでインストールする。
Linuxからpywinrmを用いてWinRM経由でWindowsを操作する場合、まず以下のコマンドをWindows側で実行しWinRMを有効にする。
winrm qc
winrm set winrm/config/client/auth '@{Basic="true"}'
winrm set winrm/config/service/auth '@{Basic="true"}'
winrm set winrm/config/service '@{AllowUnencrypted="true"}'PS C:\Users\Administrator> winrm qc
WinRM サー...CentOS 7にPython 3.4およびpip3をインストールする必要があったので、その備忘。
以下のコマンドでインストールできる。

Pythonでは、コンソール上から簡易的にWebサーバを立ち上げる事ができる。
以下のようにコマンドを実行することで、カレントディレクトリ配下をWEB公開ディレクトリとしてWEBサーバを動作させることが出来る。
※ポート番号を指定しない場合、デフォルトで8000ポートを利用する。
python -m SimpleHTTPServer <ポート番号>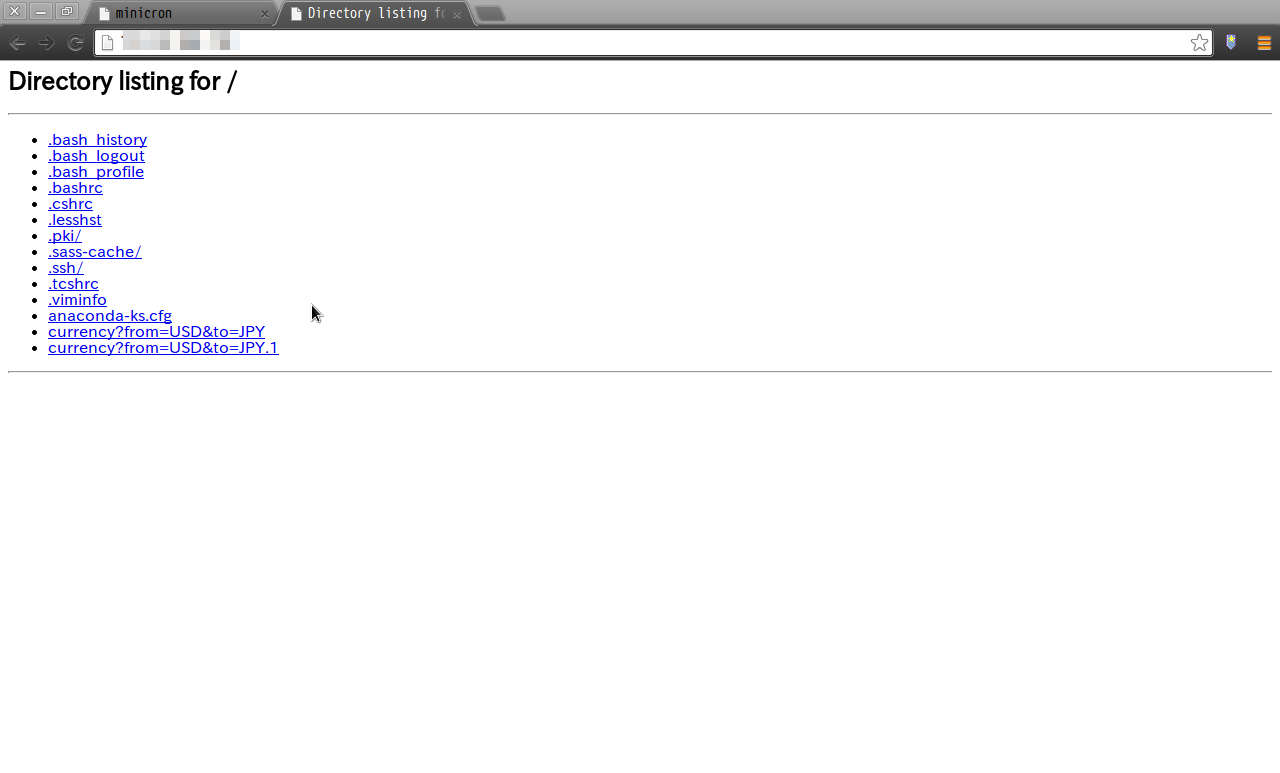
ログは全て標準出力で出力される。

忘れないようにいろいろ書き溜めてる備忘録