前にgrepでひらがな・カタカナ・漢字を抽出する方法について書いてたことがあったけど、先日置換が必要になったので念の為残しておく。
PerlのUnicodeプロパティスクリプトを使った置換(perl)
置換と言ったらsedなのだけど、残念ながらPerlのUnicodeプロパティスクリプト(\p{Hiragana}みたいな指定)がsedでは使えない。
なので、Perlで置換処理を実行する必要がある。
# perlでひらがなだけを置換する場合
command... | perl -C -ple 'use utf8;s/\p{Hiragana}/_/g'
$ cat a....
ふと、バイナリファイルの置換とかってどうやるのかなと思ってググってみたのだが、実はそれ専用のコマンドでbbeというものがあることを知った。
sedと同じような構文で、より効率的にバイナリの置換処理ができるらしい。
ちょっと便利そう。
1. インストール
MacOSや比較的メジャーなディストリであれば、普通にパッケージ管理ツールからのインストールができる。
# MacOSの場合
brew install bbe
# aptの場合
sudo apt install bbe
# pacman
sudo pacman -S bbe
少し前(というか2019年の年末)に、Twitterでファイルをコマンドで利用したあとにリダイレクトで上書きしてはいけないよねというツイートがあった。
これは結構やってしまう(そしてやらかして学習する)人が多いと思うのだけど、shellの解釈の順序の関係でコマンドの処理より先にリダイレクトの処理が...
先日実施された第45回シェル芸勉強会に出席してきたので、その復習。
前回の45回はawkでゴリゴリ解いていくような問題が多かったのだけど、今回はいろんなコマンドを組み合わせて解いていくような問題が多めになっているらしい。
問題および模範解答はこちら。あと、問題を解くに当たって必要になるファイルは以下のコマンドで取得してくる。
git clone https://github.com/ryuichiueda/ShellGeiData
Q1.
csvファイル「data.csv」に、日別のトマト・バナナ・ピーマンの売れた個数が書かれているので、それぞれが記録されている最後の日の日付...

時折、sedで置換する際にエスケープシーケンスを使って文字の色を指定したい場合というのがあると思うけど、それについて今まで把握してなかったので備忘で残しておく。
sedでエスケープシーケンスを表現する場合、残念ながらechoのときのように\eとかで表現しても置換できない。じゃあどうすればいいのかというと、エスケープを文字コード(\x1b)で記述してやることで表現できる。
sed 's//\x1b[32m\x1b[0m/g;'
実際に動かしてみるとこんな感じ。
ちゃんと色が付与されているのがわかる。
数年前に、他のターミナルの操作をのぞき見できるttylogというツールについて書いてたのだけど、そのツールの動作を調べてGolangで書き直したという内容の記事を見かけた。
読んでいると、どうやらttylogは以下のステップで他のターミナルの内容をのぞき見しているらしい。
- ttyのログインプロセスのIDを調べる
- pidに対してstraceコマンドを使ってシステムコール(read/write)を見る
- straceの内容を加工して出力する
…あれ?
このくらいの内容なら、straceを使ってgrepや...
Typoしたものが大半なのだけど、指定した文字列とN文字違ったり、1文字ずれている(「あいうえお」→「いあうえお」みたいな)文字列をヒットさせたいということがごくごくたま~にあって、それをgrepでときどきやっている。
個人のマシンではfunctionを作ってあるのだけど、たま~にリモートマシンで使うとき(+ローカルのrcファイルを読み込ませてない時)なんかにはその場でコマンドを組み合わせたりしているので、備忘で残しておく。
1文字違う文字列をgrepする
指定した文字列から1文字違う文字列をgrepする場合、以下のようにする。
文字列のNグラムをシェル芸で出す場合、色々とやり方があるようなので、念の為忘れないように残しておく。
前に「響け!ユーフォニアム」でNグラムを生成していた場合は、以下のようにsedでループさせる方法で行っていた。
echo 響け!ユーフォニアム|sed ':a;p;s/\(.\)\(.*\)/\2\1/;ba' | head
blacknon@BS-PUB-UBUNTU-01:~$ echo 響け!ユーフォニアム|sed ':a;p;s/\(.\)\(.*\)/\2\1/;ba' | head
響け!ユーフォニアム
け!ユーフォニアム響
!ユーフォニアム響け
ユーフォニアム響け...
ふと、sedで文字列を1文字ずつ入れ替えた一覧(「ちんすこう」が「ちんこすう」になってるなど)を作りたいと思ったので、やってみることにした。
まぁ、そんなに難しいことはなく、以下のようにコマンドを実行すればできる。
echo あいうえお | (a=$(cat);seq 0 $((${#a}-1))|xargs -n1 -I@ bash -c "echo $a|sed -r 's/(.{@})(.)(.)/\1\3\2/'")
blacknon@BS-PUB-UBUNTU-01:~$ echo あいうえお | (a=$(cat);seq 0 $((${#a}-1))|xargs...
以前、『メディア芸術データベース』のAPIからジャンプで打ち切られたマンガの一覧を取得しようと試みた事があったのだが、今回はより正確性を高めるためにWikipediaのジャンプの連載一覧から打ち切りマンガの一覧を作成してみる。
正直、スクレイピングならPythonでpandasとか使ったほうが楽だったりするのだけど、最初にシェル芸でやると決めたので初志貫徹やってみた。
ちょっと汚いけど、以下のようにコマンドを実行することで一年以内で連載が終わってしまった(短期集中や遺跡、続編を除く)作品の一覧を作成できる(こっちにも念の為残してある)。
(多分もうちょっときれいにできるだろうけど、そん...
ちょっと前にシェル芸botで遊んでた際、全角スペースのある箇所に文章を差し込めないかなと試したことがあったので、備忘として残しておく。
以下のように、ブレース展開を利用してsedのコードを生成してやることで対応ができる。
先日実施された、第36回シェル芸勉強会に参加してきたので、その復習。なんか、ブログの記事自体をすごく久しぶりに書いた気がする(個人的にRustで簡単なツール作ってるのだけど、難しすぎてそっちにリソース全振り中…。ある程度動くようにはなったけどいつ終わるのやら…簡単なはずだったのに…)。
大体いつもむずかしめの問題が多いのだけど、今回も難しかった。
問題及び模範解答はこちら。最初に、問題等に使用するファイルをgitからcloneしておくといい。
Q1.
「welcome.txt」というファイルに隠されたメッセージを読み取れ、という内容。
単純にcatしただけだとアンダーバーし...
最近、ほぼ毎日何らかの形でTwitterのシェル芸botで遊んでるのだけど、そこで文字列からひし形の模様を作って遊んでたので、そのシェル芸について備忘で残しておく。
(こういう遊び、ちゃんと名前付いてるのかもしれないけど、わからないのでこの書き方で。)
1. 文字列でひし形にする
文字列を使って、以下のような模様を作る(例:焼き肉が食べたい)。
縦横ともに、真ん中の列・行はオリジナルの文が読める状態。
焼
焼肉が
焼肉が食べ
焼肉が食べたい
が食べたい
べたい
い
最初、jqコマンドだけで実現できるかと思ったのだけど、ちょっと計算の仕方があわず。
a...
ちょっとシェル芸botで遊んでいた際、ふと畳語(ワンワンとかドキドキとかムラムラ、ビンビン、ヌレヌレなど、反復する言葉)を抽出したり、置換するにはどうすればいいかなと思ったので、やってみることにした。
なお、grepやsedについては使用するのはGNU拡張されたものを用いるので、Mac OS Xに入っているgrepやsedでは同じことができないかもしれないので注意。
1.抽出する場合
GNU grepにはPerl正規表現を利用できるオプションがあるので、以下のように記述することで畳語を抽出できる。
(Perlの正規表現を使うことでunicode propertiesが利用できるよう...
Twitterをボケーッと眺めてたところ、そんな感じの処理についてを見かけたので、処理方法についてを残しておく。
sedでは、以下のように指定することで指定行の範囲(以下の例では、n~m行目)でのみ処理を行わせる事が可能となっている。
sed 'n,m s/$/*/g'
blacknon@BS-PUB-UBUNTU-01:~$ seq 10 | sed '2,4 s/$/*/g'
1
2*
3*
4*
5
6
7
8
9
10
で、今回はこの範囲指定を複数(例えば2,4と6,8)指定して、同じ処理を行わせようという内容。
個人的には、こういった場合はブレース展開を利用する方法を...
ふと、特定の文字列同士を入れ替える(パターンに応じて文字列の置換をさせる)処理をワンライナーでさせるにはどうすればいいかなと思ったので、ちょっと調べてみた。
sedの場合
sedの場合、よく思いつくのが以下の様に一度別の文字列に置換してから処理をするやり方。
コマンド | sed 's/パターンA/\x0/g;s/ぱたーんB/パターンA/g;s/\x0/ぱたーんB/g'
blacknon@BS-PUB-UBUNTU-01:~$ echo -e "「あいうえお」と「かきくけこ」\nそして、「かきくけこ」と「ABCDE」、「あいうえお」"
「あいうえお」と「かきくけこ」
そして、「...
コンソール上で全角文字⇔半角文字の変換を行う事が時たまあるのだけど、どんな方法があるかなと思ったのでちょっと調べてみた。
nkfを使う(全角→半角のみ)
nkf -Zを用いることで、全角数字→半角数字への変換が可能だ。
ただ、残念ながら半角→全角はできないようだ。
nkf -Z # 全角→半角
blacknon@BS-PUB-DEVELOP:~$ echo Abcd0123456789 | nkf -Z
Abcd0123456789
uconvを使う
個人的にお気に入りのツールにuconvというツールがあるのだが、これを使うことでも半角→全角、全角→半角変換が可能...
個人的に、よく桁数が多い数字を読む際に、以下のような感じでprintfを使ってカンマ区切りにして読みやすくしている。
echo 1213141516171819 | printf "%'d\n" $(cat)
blacknon@BS-PUB-DEVELOP:~$ echo 1213141516171819 | printf "%'d\n" $(cat)
1,213,141,516,171,819
ただ、これでも桁数が多いと「日本語でなんだっけこの数字…?(´・ω・`)」となって読めない事が多々ある(1,000億くらいまでならパット見でいけるけど…)ので、シェル芸で数字に単位を付けて...
先日実施された、第35回シェル芸勉強会に参加してきたのでその復習(第34回は腰をやって参加してないので、1個空いちゃったなー…)。
今回は、前半はそこまで厳しく無かったのだが、後半が結構難しかったので中々疲れた。
問題及び模範解答はこちら。最初に、問題等に使用するファイルをgitからcloneしておくといい。
git clone https://github.com/ryuichiueda/ShellGeiData.git
Q1.
ちょっと前に話題になっていた、curlでアクセスするとアスキーアートのParty Parrotがターミナル上で動き出すサービスをの出力をファイル...
先日、Twitterでこんなツイートを見かけた。
ふとした思いつきで、アラビア数字から漢数字への変換をコンソール上でできないかなーと思ったのでやってみることにした。
以下のように、まず一度sedで全部漢数字に切り替えて、その後は各桁に応じて漢字の置き換えをしていくことで対応できるようだ。
echo 123456789 | sed 'y/0123456789/〇一二三四五六七八九/' | grep -o . | tac | paste - <(echo {十,百,千,万,十,百,千,億} | fmt -1 | cat <(echo) -) | grep -vE ^$'\t' | tac | sed -zr 's/(\t|\n)//g'| perl -lpe 's/一(?!($|万|億))//g;s/〇(?!$)//g'
Twitterでそういった処理について見かけたので、やってみた内容を備忘として残しておく。
sedでやる場合
GNU拡張されたsedの場合 -i で上書きができるので、ただ文字列を挿入するだけであれば以下のようにしてやればいい。
sed -i '1iString' *.txt
[root@BS-PUB-CENT7-01 test_dir]# cat a.txt
a01 a02
a03 a04
a05 a06
a07 a08
a09 a10
a11 a12
a13 a14
a15 a16
a17 a18
a19 a20
[root@BS-PUB-CENT7-01 test_d...
先日のシェル芸勉強会の問題を解いている際、sedでブレース展開させてその値を置換後の値として利用させる方法を思いついたので、忘れないように備忘で残しておく。
といっても、実際やってることは前に書いた複数回ごとにヒットした箇所に対しての置換処理の応用みたいなものなんだけど。
処理方法だが、以下のようにsedを実行することで置換後の値にブレース展開をした値を順番に置き換えていく事ができる。
echo {a..g} | sed 's/ /\n \n/g' | sed -z -e's/ /'{1..100}'/'
忘れやすいので、備忘として残しておく。
sedで行範囲(n~m行)とパターン(指定した文字列を含むか否か)を同時に満たしている行に対してのみ処理を行いたい場合、以下の様にする。
コンソール上で、複数ファイルの行を交互に出力させる処理について見かけて実際にやってみたので、記録として残しておくことにする。
基本的にはpasteコマンドを利用する事で対応する。
1. 複数ファイルの内容を1行ごとに交互に出力させる
単純に、複数ファイルの内容を1行ごとに交互に出力させる場合。
この場合は、pasteでデリミタを改行にして以下のように出力させればいいだけだ。
paste -d'\n' file1 file2 # ファイルの場合
paste -d'\n' <(command1) <(command2) # コマンドの実行結果を利用する場合
blacknon@BS-...
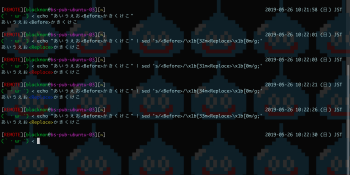
以前にsedでn個目~n個目までにヒットした箇所のみを置換する処理について記述したが、今回は奇数・偶数回目にヒットした箇所、n回目ごとにヒットした箇所のみを置換する処理についてを備忘として残しておくことにする。
基本は同じで、ブレース展開を使って置換処理についての箇所を生成させるというもの。
以下、実行例。
sed -e's/before/after/'{1,{2..1000..1}} # 奇数ごとの場合
sed -e's/before/after/'{2,{3..1000..1}} # 偶数ごとの場合
sed -e's/before/after/'{n,{(n*2-1)..1000....
コンソール上で、同じ文字の繰り返し(ゾロ目とか)を抽出、置換したいことがあったので、備忘で残しておく事にする。
抽出する場合は、以下のようにgrepで正規表現を書いてやる。
Nのトコはゾロ目の数-1の数字を入れてやる。
grep -oE '(.)\1{N}'
[root@BS-PUB-CENT7-01 test_dir]# seq -w 0 999 | grep -E '(.)\1{2}'
000
111
222
333
444
555
666
777
888
999
置換する場合も同様で、sedで以下のように記述してやればいい。
コンソール上で文字列を融合( パトカー と タクシー であれば、パタトカクシーー)する処理について、ワンライナーで記述してみたので備忘として残しておく。
echo パトカー タクシー|sed -z 's/ /\n/g;s/\B/ /g'|rs -T|tr -d ' \n'
eval 'paste -d ""' \<\(echo\ {パトカー,タクシー}'|grep -o .)'|tr -d '\n'
一部の処理をjqコマンドでやった場合は以下。
こういった処理の場合だと、jqにはあまり向いてないようだ。
(2個目のやつは@ebanさんのやり方を参考にした。)
...
sedでは四則演算とかの計算処理については対応していないのだが、bashと組み合わせる事で計算処理ができないかとやってみたので備忘で残しておく。
で、結論としては以下のように、e(置換や抽出した内容を元に組み立てたコマンドを実行する) を利用することで、bashで $((計算式)) をechoさせることで計算をさせることができる。
echo 1234 | sed 's/[0-9]*/echo $((& + 1111))/ge'
blacknon@BS-PUB-UBUNTU-01:~$ echo 1234 | sed 's/[0-9]*/echo $((& + 1111))/ge...
ここでそんな感じの処理について見かけたので、シェル芸で文章中からの単語の集計(例:「ABCDandABCDorABCDsoABCD」だと、ABCDが4回使われているなど)をシェル芸で一発でできないかなと思ったので、試しにやってみることにした。
まず、文章の中から単語を取得する必要があるのだが、形態素解析だと対象が文章ではなくバラバラな羅列だった場合に使えないので、文章中から1文字づつ範囲をずらして文字を抽出し、それを集計することで使われている文字列を取得することにした。
で、ちょっと長いけど以下のようにすることで、複数回出現した文字列の組み合わせが取得できる。
echo ABCDan...