を調べる")
前に、「〇んこ」みたいな伏字の候補をシェル芸で見つけたりしてたのだが、ふと「類義語」ってコンソール上で得ることができないのかな…?と思い調べてみた。
調べてたら「日本語WordNet」なる日本語辞書のプロジェクトがあるらしい。 基本は辞書ファイル(sqlite3)をダウンロードして使うようなのだが、こちらにWebから検索できるものがあった。 ということはスクレイピングをすればいけるだろうということで、実際にやってみることにした。
で、その結果。 grepだけで抽出できるかと思ったけど、ちょっとうまくいかなかった。
curl -s --data "lemma=ちんこ&lang=jpn&lang2=jpn" 'http://compling.hss.ntu.edu.sg/omw/cgi-bin/wn-gridx.cgi?usrname=&gridmode=gridx' | grep -oP '(?=<span [^>]*>?).*?(?=</span>)' | awk -F\> '{print $2}'
curl -s --data "lemma=わんこ&lang=jpn&lang2=jpn" 'http://compling.hss.ntu.edu.sg/omw/cgi-bin/wn-gridx.cgi?usrname=&gridmode=gridx' | grep -oP '(?=<span [^>]*>?).*?(?=</span>)' | awk -F\> '{print $2}'blacknon@BS-PUB-UBUNTU-01:~$ curl -s --data "lemma=ちんこ&lang=jpn&lang2=jpn" 'http://compling.hss.ntu.edu.sg/omw/cgi-bin/wn-gridx.cgi?usrname=&gridmode=gridx' | grep -oP '(?=]*>?).*?(?=)' | awk -F\> '{print $2}'
ちんちん
ちんこ
おちんちん
ぽこちん
ちんぽこ
ちんぽ
まら
blacknon@BS-PUB-UBUNTU-01:~$ curl -s --data "lemma=わんこ&lang=jpn&lang2=jpn" 'http://compling.hss.ntu.edu.sg/omw/cgi-bin/wn-gridx.cgi?usrname=&gridmode=gridx' | grep -oP '(?=]*>?).*?(?=)' | awk -F\> '{print $2}'
ワンワン
わんわん
わんこ
わんちゃん
元の単語は一文字しか違わないのに…(´・ω・`)。 ちなみに、"lang2"の値を書き換えることで、英語などほかの言語で結果を得ることもできる(日本語の分も表示される)。
curl -s --data "lemma=ちんこ&lang=jpn&lang2=eng" 'http://compling.hss.ntu.edu.sg/omw/cgi-bin/wn-gridx.cgi?usrname=&gridmode=gridx' | grep -oP '(?=<span [^>]*>?).*?(?=</span>)' | awk -F\> '{print $2}'
curl -s --data "lemma=わんこ&lang=jpn&lang2=fra" 'http://compling.hss.ntu.edu.sg/omw/cgi-bin/wn-gridx.cgi?usrname=&gridmode=gridx' | grep -oP '(?=<span [^>]*>?).*?(?=</span>)' | awk -F\> '{print $2}'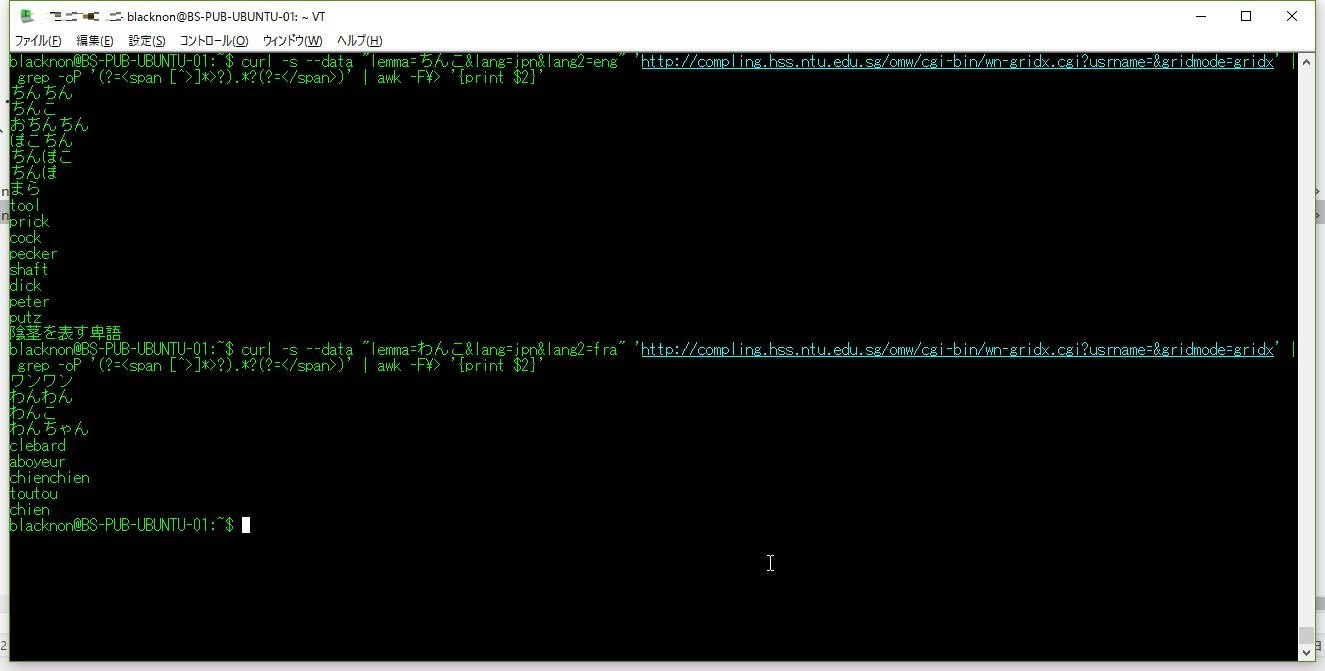
そして、かなり長くはなるが、伏字の単語すべての類義語を調べるのがこれだっ!
echo "○んこ" | sed 's/○/./g' | xargs -I{} sh -c "curl -s http://web-apps.nbookmark.com/hatena-dic/hatena_msime_nocomment.zip | zcat | iconv -f UTF-16 -t UTF-8 | awk '\$1~ /^{}$/{print \$1}' | uniq" \
| xargs -n 1 -I{} sh -c 'curl -s --data "lemma={}&lang=jpn&lang2=jpn" "http://compling.hss.ntu.edu.sg/omw/cgi-bin/wn-gridx.cgi?usrname=&gridmode=gridx" | grep -oP "(?=<span [^>]*>?).*?(?=</span>)" | awk -F\> "{print \$2}" | tr "\\n" " ";echo "\n"' \
| grep -v ^$
…うっわ(( •´д•` )ドンビキ)。 やっといてなんだけど、さすがに並んでる言葉がひどすぎたのでモザイクかけた。
たぶん、ひらがなで引っ張ってこれるキーワードだったからろくでもない類義語だけ引っかかったっぽい。 漢字で検索させれば、もうちょっと綺麗な言葉も並んだ…とは思う。

