
Twitterでそんなのあったので、いつか自分にも必要なときが来るかもしれないので備忘で残しておく。 圧縮ファイルの中身が、サイズが少なくてほとんど差異が無いのであれば、以下のように比較してやると楽に差異が確認できる。
diff -y <(unzip -c test1.zip) <(unzip -c test2.zip)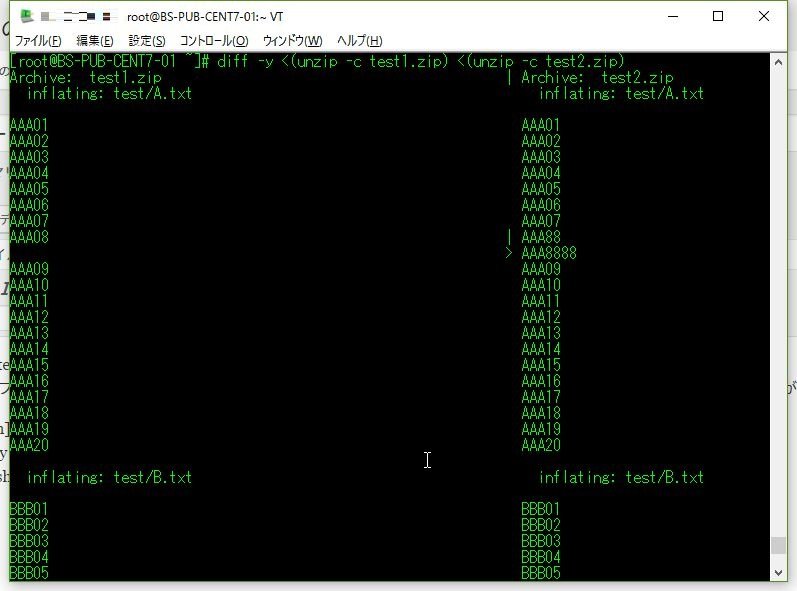
でもこれ、目diffをちょっとやりやすくしただけでなかなかツライよなぁ… もうちょっとなんとかならないかなと思ったので、無理やり以下のように圧縮ファイル内の各ファイルごとにdiffをかけさせてみた。
(X="test1.zip" Y="test2.zip";echo "unzip -l "{$X,$Y}"@" | xargs -d@ -n1 sh -c | awk '$1 != 0 && $2 ~ /^[0-9]/ {print $4}' | sort -u | xargs -I@ bash -c "echo @;diff <(unzip -p $X @) <(unzip -p $Y @)")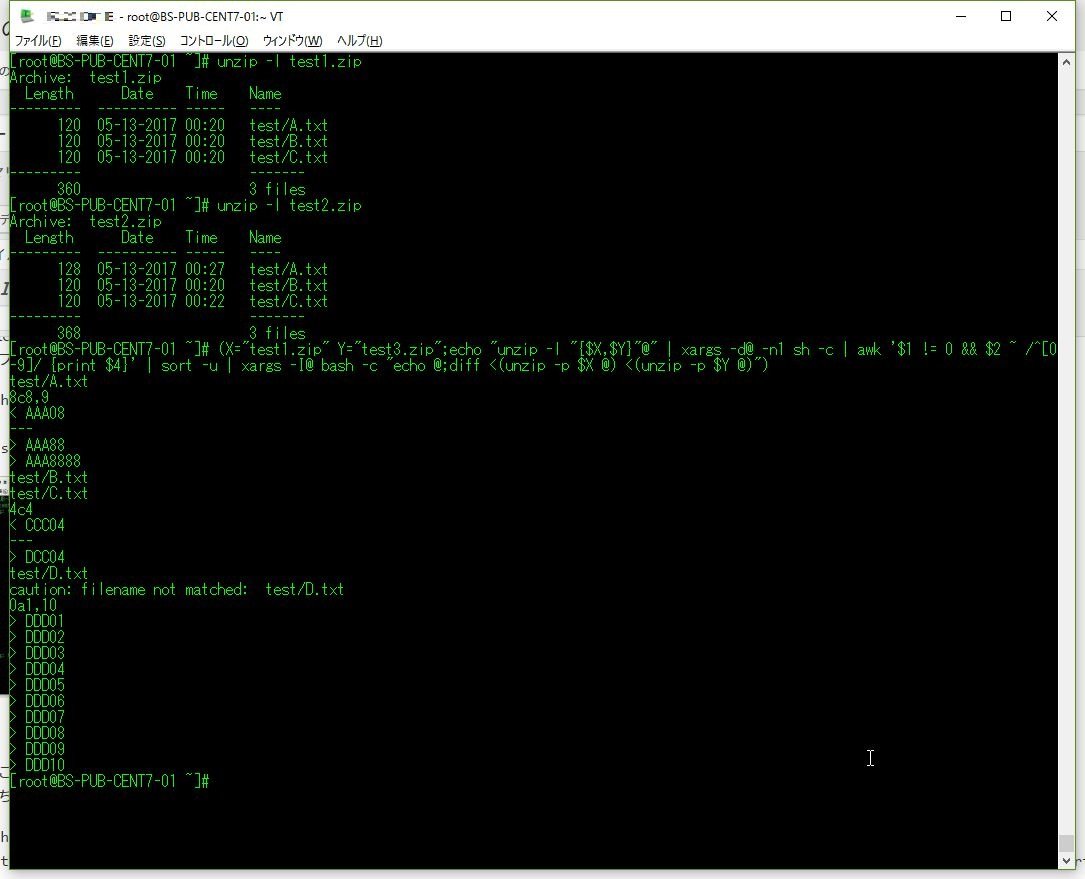
[root@BS-PUB-CENT7-01 ~]# unzip -l test1.zip
Archive: test1.zip
Length Date Time Name
--------- ---------- ----- ----
120 05-13-2017 00:20 test/A.txt
120 05-13-2017 00:20 test/B.txt
120 05-13-2017 00:20 test/C.txt
--------- -------
360 3 files
[root@BS-PUB-CENT7-01 ~]# unzip -l test2.zip
Archive: test2.zip
Length Date Time Name
--------- ---------- ----- ----
128 05-13-2017 00:27 test/A.txt
120 05-13-2017 00:20 test/B.txt
120 05-13-2017 00:22 test/C.txt
--------- -------
368 3 files
[root@BS-PUB-CENT7-01 ~]# (X="test1.zip" Y="test3.zip";echo "unzip -l "{$X,$Y}"@" | xargs -d@ -n1 sh -c | awk '$1 != 0 && $2 ~ /^[0-9]/ {print $4}' | sort -u | xargs -I@ bash -c "echo @;diff <(unzip -p $X @) <(unzip -p $Y @)")
test/A.txt
8c8,9
< AAA08 --- > AAA88
> AAA8888
test/B.txt
test/C.txt
4c4
< CCC04 --- > DCC04
test/D.txt
caution: filename not matched: test/D.txt
0a1,10
> DDD01
> DDD02
> DDD03
> DDD04
> DDD05
> DDD06
> DDD07
> DDD08
> DDD09
> DDD10…ちょっと(だいぶ)ごちゃっとしてるけど、とりあえず良いか。 もうちょっとキレイに書けそうな気もするけど、どうなんだろう。

