")
第29回シェル芸勉強会に行ってきたので、その復習。
今回はちゃんと起きれた(?)ので、午前にも最初から参加することができた。 午前の部はPerlのワンライナー入門とのことで、鳥海さんが講師。 使ったスライドはこちら。
便利そうな定義済の変数が結構いっぱいあるみたいなので、ちゃんと覚えないとなぁ…。 次回はPerlの正規表現になるらしい。
午後はいつもどおり、8個の問題を解いていく。 問題・解説はこちら。 今回は3つのテーマ(join等によるファイルの結合、パズル、大きい文字を扱った問題)で問題が構成されている。
個人的には、今回は地味にお気に入りのコマンドだったdatamashが地味にハマったのが嬉しかった。
Q1.
2つのファイル「kadai1」「kadai2」を集計して、合計の金額を取得するよ、という問題。 最初の問題だったので、これは比較的時間内に解答しやすかった。
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat kadai1
001 山田 20
002 出川 30
005 鳥海 44
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat kadai2
001 山田 20
003 上田 15
004 今泉 22
005 鳥海 44とりあえず、ちゃちゃっとawkでグループ集計を行った。
awk '{s[$1" "$2]+=$3}END{for(i in s){print i,s[i]}}' kadai{1,2} | sort -k1blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ awk '{s[$1" "$2]+=$3}END{for(i in s){print i,s[i]}}' kadai{1,2} | sort -k1
001 山田 40
002 出川 30
003 上田 15
004 今泉 22
005 鳥海 88後は、datamashで以下のようにすることで集計処理が行える。
cat kadai{1,2} | sort | datamash -t' ' -g 1,2 sum 3blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat kadai{1,2} | sort | datamash -t' ' -g 1,2 sum 3
001 山田 40
002 出川 30
003 上田 15
004 今泉 22
005 鳥海 88Q2.
Q2は、既存の講義の出欠データ(attend)に、最新の講義の出席者(attend6)を足して最新の出欠データを作成するという内容。
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat attend
001 山田 出出欠出出
002 出川 出出欠欠欠
003 上田 出出出出出
004 今泉 出出出出出
005 鳥海 欠出欠出欠
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat attend6
001,005,003とりあえず、無理やり解いてみた。書き方汚い…。
cat attend6|tr , '\n'|sort -n|sed 's/$/ 出x/g'|join -a1 attend -|sed -e '/x$/!s/$/ 欠x/g' -e 's/x$//g'|awk '{print $1,$2,$3""$4}'blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat attend
001 山田 出出欠出出
002 出川 出出欠欠欠
003 上田 出出出出出
004 今泉 出出出出出
005 鳥海 欠出欠出欠
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat attend6
001,005,003
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat attend6|tr , '\n'|sort -n|sed 's/$/ 出x/g'|join -a1 attend -|sed -e '/x$/!s/$/ 欠x/g' -e 's/x$//g'|awk '{print $1,$2,$3""$4}'
001 山田 出出欠出出出
002 出川 出出欠欠欠欠
003 上田 出出出出出出
004 今泉 出出出出出欠
005 鳥海 欠出欠出欠出@ebanさんがawk、@grethlenさんがsed単体で解いてたので、以下参考。
Q2 % awk '!f{a=$0;next}{print $0(a~$1?"出":"欠")}' attend6 f=1 attend #シェル芸
— eban (@eban) 2017年7月1日
A2:sedだけでいけたな
sed 's/$/欠/' attend | sed -r "/^($(sed 's/,/|/g' attend6))/{s/.$/出/g}"#シェル芸— ぐれさん (@grethlen) 2017年7月1日
Q3.
Q3では、テストの点(test)と出欠データ(attend)を組合せ、出席率が過半数に満たない場合、テストを受けてない場合は0点として集計をする問題(過半数以上出席してテスト受けてれば、その点数が成績になる)。
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat test
001 90
002 78
004 80
005 93
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat attend
001 山田 出出欠出出
002 出川 出出欠欠欠
003 上田 出出出出出
004 今泉 出出出出出
005 鳥海 欠出欠出欠時間内に解けなかったのだが、とりあえず復習で以下のように出せた。
join -a 1 attend test | awk '{a=$3;if(gsub("出","",a)>2){x=$4}else{x=0};print $1,$2,$3,0+x}'blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ join -a 1 attend test | awk '{a=$3;if(gsub("出","",a)>2){x=$4}else{x=0};print $1,$2,$3,0+x}'
001 山田 出出欠出出 90
002 出川 出出欠欠欠 0
003 上田 出出出出出 0
004 今泉 出出出出出 80
005 鳥海 欠出欠出欠 0あとは、@ebanさんの解答が参考になりそう。午前にやったPerlの三項演算子の書き方、awkでも使えるのかー。
Q3 % join -a 1 attend test | awk '{print $1,$2,(gsub("出","",$3)>2?+$4:0)}'
001 山田 90
002 出川 0
003 上田 0
004 今泉 80
005 鳥海 0#シェル芸— eban (@eban) 2017年7月1日
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ join -a 1 attend test | awk '{print $1,$2,(gsub("出","",$3)>2?+$4:0)}'
001 山田 90
002 出川 0
003 上田 0
004 今泉 80
005 鳥海 0
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ join -a 1 attend test | awk '{print $1,$2,$3,(gsub("出","",$3)>2?+$4:0)}'
001 山田 出出欠出出 90
002 出川 出出欠欠欠 0
003 上田 出出出出出 0
004 今泉 出出出出出 80
005 鳥海 欠出欠出欠 0参考
上記コマンドの、awkの三項演算子のトコだけ別のやり方でやってみた
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat kadai1
001 山田 20
002 出川 30
005 鳥海 44
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ # 3列目が30の場合は1、それ以外は2を出力
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat kadai1 | awk '{print ($3==30?1:2)}'
2
1
2Q4.
Q4.1
以下のように、echoでマイナスを含む数字を出力して、それを同じ桁数のものであれば同じ行に出力させる。
echo -1 4 5 2 42 421 44 311 -9 -11Q4.1に関しては、以下のように awkで記述することで対応できる。
echo -1 4 5 2 42 421 44 311 -9 -11 | sed -z 's/ /\n/g' | sort -n | awk '{x=length($0);if(x!=p)print "";p=x;printf $0" "}'| awk NF
echo -1 4 5 2 42 421 44 311 -9 -11 | sed -z 's/ /\n/g' | sort -g | awk '{x=length($0);printf (x!=p ? "\n" : " ") $0;p=x}'| awk NF #三項演算子を使ったパターンblacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ echo -1 4 5 2 42 421 44 311 -9 -11 | sed -z 's/ /\n/g' | sort -n | awk '{x=length($0);if(x!=p)print "";p=x;printf $0" "}'| awk NF
-11
-9 -1
2 4 5
42 44
311 421
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ echo -1 4 5 2 42 421 44 311 -9 -11 | sed -z 's/ /\n/g' | sort -g | awk '{x=length($0);printf (x!=p ? "\n" : " ") $0;p=x}'| awk NF #三項演算子を使ったパターン
-11
-9 -1
2 4 5
42 44
311 421Q4.2
Q4.2では、Q4.1で扱った数字の一部に+記号が付与された状態で使用する。 ここで知ったのだが、sortで+記号のついた数字を普通の数字としてソートする場合、-gオプションを使用すると良いようだ。
で、後はQ4.1でawkを使って文字の長さを取得する際、数字として取得させれば良いようだ。
echo -1 +4 5 2 42 421 44 311 -9 -11 | sed -z 's/ /\n/g' | sort -g | awk '{x=length(int($0));if(x!=p)print "";p=x;printf $0" "}'| awk NF
echo -1 +4 5 2 42 421 44 311 -9 -11 | sed -z 's/ /\n/g' | sort -g | awk '{x=length(int($0));printf (x!=p ? "\n" : " ") $0;p=x}'| awk NF #三項演算子を使ったパターンblacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ echo -1 +4 5 2 42 421 44 311 -9 -11 | sed -z 's/ /\n/g' | sort -g | awk '{x=length(int($0));if(x!=p)print "";p=x;printf $0" "}'| awk NF
-11
-9 -1
2 +4 5
42 44
311 421
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ echo -1 +4 5 2 42 421 44 311 -9 -11 | sed -z 's/ /\n/g' | sort -g | awk '{x=length(int($0));printf (x!=p ? "\n" : " ") $0;p=x}'| awk NF #三項演算子を使ったパターン
-11
-9 -1
2 +4 5
42 44
311 421
Q5.
以下のファイル(triangle)の三角形を、右に回転させてやるという問題。
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat triangle
1
3 9
7 a 6
8 4 2 5最初はやり方がわからなかったのだが、試しに行列置換をしてみたところうまくいけた。 rsコマンドでもいけるのだが、今回はdatamashを使って行列置換をして、その後printfでスペース埋めをして反転させることで対処できた。
cat triangle | datamash -t' ' transpose | xargs -d'\n' printf '%-7s\n' | revblacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat triangle
1
3 9
7 a 6
8 4 2 5
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ # datamashで行列置換
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat triangle | datamash -t' ' transpose
8
7 4
3 a 2
1 9 6 5
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ # 右側をスペース埋めするため、xargsでprintfに渡す
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat triangle | datamash -t' ' transpose | xargs -d'\n' printf '%-7s\n' | cat -e
8 $
7 4 $
3 a 2 $
1 9 6 5$
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ # 左右反転させる
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat triangle | datamash -t' ' transpose | xargs -d'\n' printf '%-7s\n' | rev
8
4 7
2 a 3
5 6 9 1ちなみに逆回転(5が一番上に来るやつ)だと、以下のようにコマンドを実行してやることでできた。 ちょっと長くなってしまった…
cat triangle | xargs -d'\n' printf '%-7s\n' | rev | sed 's/\s*$//g' | datamash -t' ' transpose | xargs -d'\n' printf '%-7s\n' | revblacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat triangle | xargs -d'\n' printf '%-7s\n' | rev | sed 's/\s*$//g' | datamash -t' ' transpose | xargs -d'\n' printf '%-7s\n' | rev
5
2 6
4 a 9
8 7 3 1ちなみに、rsコマンド版については@ebanさんが記述してくれていた。 やはり、こちらのほうが短く書けている。
Q5 rsで一応
% cat triangle|rs -T -c' ' -g1|rev|awk '{printf "%*s\n",11-NR,$0}'|sed 's/ *$//'
8
4 7
2 a 3
5 6 9 1#シェル芸— eban (@eban) 2017年7月1日
Q6.
Q6では、ファイル(prime)内にある1~100までの範囲内にある素数のうち、欠番の箇所で改行をさせるというもの。
blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ cat prime
2 3 5 7 11 13 17 19 31 37 41 43 47 53 59 67 71 73 79 83 89 97とりあえず、diffでfactorの出力と比較させ、比較時の差異を表す「>」を改行に置換する方法で解答ができる。
diff -y <(cat prime | sed -z 's/ /\n/g') <(echo {1..100} | factor | awk 'NF==2{print $2}') | awk '{gsub(">","\n",$1);printf $1" "}' | awk NF | sed 's/^ //g'blacknon@BS-PUB-DEVELOP:~/20170701/ShellGeiData/vol.29$ diff -y <(cat prime | sed -z 's/ /\n/g') <(echo {1..100} | factor | awk 'NF==2{print $2}') | awk '{gsub(">","\n",$1);printf $1" "}' | awk NF | sed 's/^ //g'
2 3 5 7 11 13 17 19
31 37 41 43 47 53 59
67 71 73 79 83 89 97Q7.
toiletコマンドで出力した「にゃーん」という文字列が記述されているhtmlファイルがあるので、それをコンソール上で出力させるという問題。 中身はhtmlファイルなので、CUIブラウザを使うことで対応ができる。 もしくは、html2textなるコマンドがあるようなので、それを使うというのも良さそうだ(なお、html2textはTeratermでは動かなかった。表示できない文字コードが使われているようだ)。
w3m -dump ファイルPATH
html2text ファイルPATH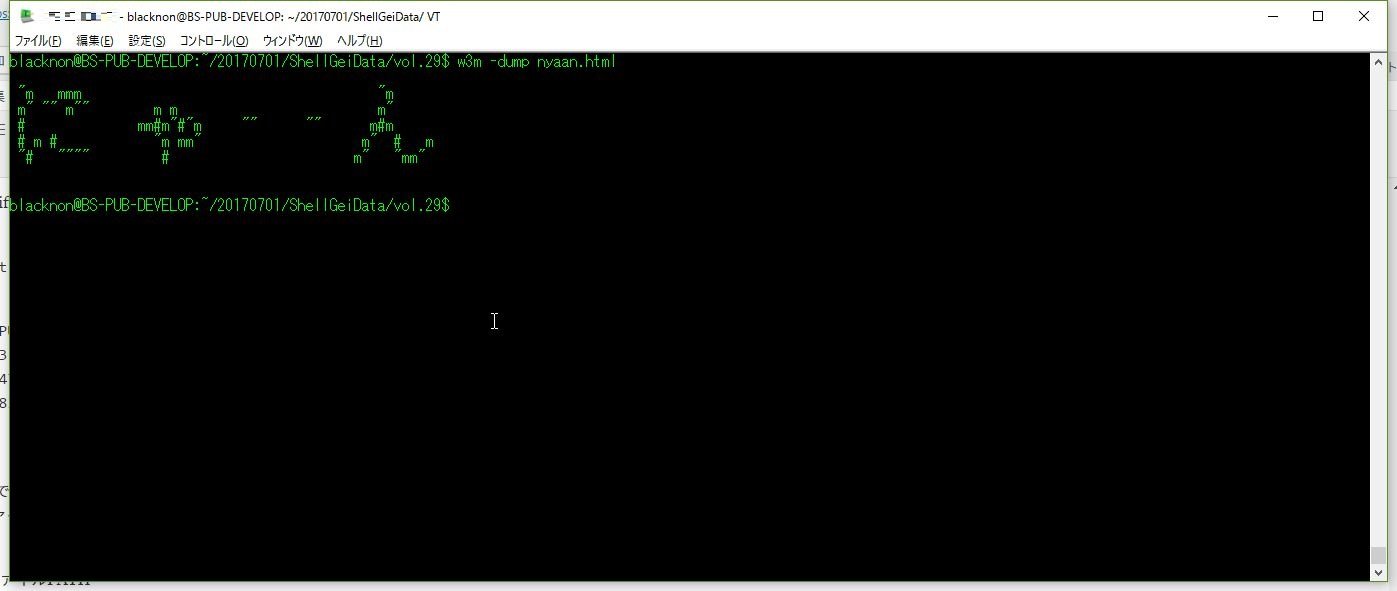
Q8.
shellgeiファイルにある「シェルゲイ」のtoilet出力を、文字詰めして表示させようという問題。 他の人の解答を参考にして、縦横変換をしてスペースしか無い行を削除することで実現。
sed 's/ /_/g;s/./& /g' shellgei|datamash -t' ' transpose|sed -r '/^_( _)+$/d'|datamash -t' ' transpose|sed 's/ //g;s/_/ /g'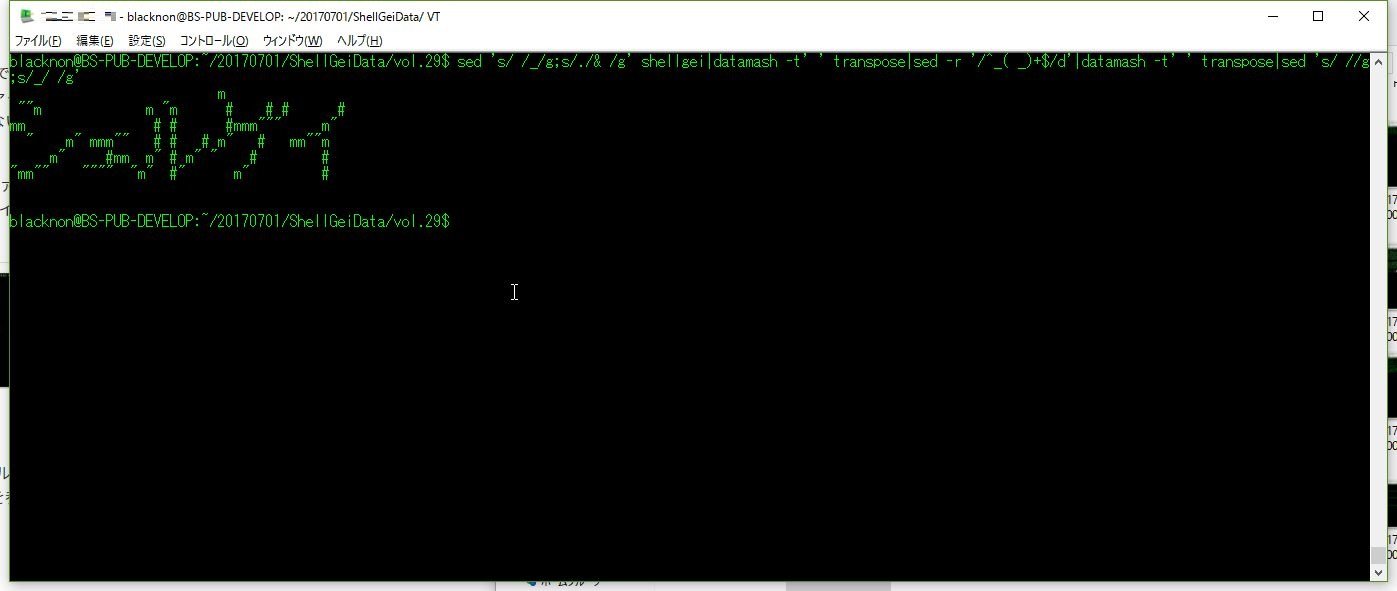
今回の裏テーマはjoinコマンドだったようなのだが、あまり理解していない事がわかった。 join、もうちょっと使って理解しないとダメだなぁ…。

